SDS-2.2, Scalable Data Science
This is used in a non-profit educational setting with kind permission of Adam Breindel.
This is not licensed by Adam for use in a for-profit setting. Please contact Adam directly at [email protected] to request or report such use cases or abuses.
A few minor modifications and additional mathematical statistical pointers have been added by Raazesh Sainudiin when teaching PhD students in Uppsala University.
Archived YouTube video of this live unedited lab-lecture:
TensorFlow
... is a general math framework
TensorFlow is designed to accommodate...
- Easy operations on tensors (n-dimensional arrays)
- Mappings to performant low-level implementations, including native CPU and GPU
- Optimization via gradient descent variants
- Including high-performance differentiation
Low-level math primitives called "Ops"
From these primitives, linear algebra and other higher-level constructs are formed.
Going up one more level common neural-net components have been built and included.
At an even higher level of abstraction, various libraries have been created that simplify building and wiring common network patterns. Over the last 2 years, we've seen 3-5 such libraries.
We will focus later on one, Keras, which has now been adopted as the "official" high-level wrapper for TensorFlow.
We'll get familiar with TensorFlow so that it is not a "magic black box"
But for most of our work, it will be more productive to work with the higher-level wrappers. At the end of this notebook, we'll make the connection between the Keras API we've used and the TensorFlow code underneath.
import tensorflow as tf
x = tf.constant(100, name='x')
y = tf.Variable(x + 50, name='y')
print(y)
<tf.Variable 'y:0' shape=() dtype=int32_ref>
There's a bit of "ceremony" there...
... and ... where's the actual output?
For performance reasons, TensorFlow separates the design of the computation from the actual execution.
TensorFlow programs describe a computation graph -- an abstract DAG of data flow -- that can then be analyzed, optimized, and implemented on a variety of hardware, as well as potentially scheduled across a cluster of separate machines.
Like many query engines and compute graph engines, evaluation is lazy ... so we don't get "real numbers" until we force TensorFlow to run the calculation:
init_node = tf.global_variables_initializer()
with tf.Session() as session:
session.run(init_node)
print(session.run(y))
150
TensorFlow integrates tightly with NumPy
and we typically use NumPy to create and manage the tensors (vectors, matrices, etc.) that will "flow" through our graph
New to NumPy? Grab a cheat sheet: https://s3.amazonaws.com/assets.datacamp.com/blog*assets/Numpy*Python*Cheat*Sheet.pdf
import numpy as np
data = np.random.normal(loc=10.0, scale=2.0, size=[3,3]) # mean 10, std dev 2
print(data)
[[ 8.4245312 10.74940182 14.22705451] [ 9.76979594 9.03838597 10.29252576] [ 10.60165571 12.10778192 6.57955182]]
# all nodes get added to default graph (unless we specify otherwise)
# we can reset the default graph -- so it's not cluttered up:
tf.reset_default_graph()
x = tf.constant(data, name='x')
y = tf.Variable(x * 10, name='y')
init_node = tf.global_variables_initializer()
with tf.Session() as session:
session.run(init_node)
print(session.run(y))
[[ 84.245312 107.49401822 142.27054512] [ 97.69795937 90.38385973 102.92525764] [ 106.01655709 121.07781918 65.79551821]]
We will often iterate on a calculation ...
Calling session.run runs just one step, so we can iterate using Python as a control:
with tf.Session() as session:
for i in range(3):
x = x + 1
print(session.run(x))
print("----------------------------------------------")
[[ 9.4245312 11.74940182 15.22705451] [ 10.76979594 10.03838597 11.29252576] [ 11.60165571 13.10778192 7.57955182]] ---------------------------------------------- [[ 10.4245312 12.74940182 16.22705451] [ 11.76979594 11.03838597 12.29252576] [ 12.60165571 14.10778192 8.57955182]] ---------------------------------------------- [[ 11.4245312 13.74940182 17.22705451] [ 12.76979594 12.03838597 13.29252576] [ 13.60165571 15.10778192 9.57955182]] ----------------------------------------------
Optimizers
TF includes a set of built-in algorithm implementations (though you could certainly write them yourself) for performing optimization.
These are oriented around gradient-descent methods, with a set of handy extension flavors to make things converge faster.
Using TF optimizer to solve problems
We can use the optimizers to solve anything (not just neural networks) so let's start with a simple equation.
We supply a bunch of data points, that represent inputs. We will generate them based on a known, simple equation (y will always be 2*x + 6) but we won't tell TF that. Instead, we will give TF a function structure ... linear with 2 parameters, and let TF try to figure out the parameters by minimizing an error function.
What is the error function?
The "real" error is the absolute value of the difference between TF's current approximation and our ground-truth y value.
But absolute value is not a friendly function to work with there, so instead we'll square it. That gets us a nice, smooth function that TF can work with, and it's just as good:
np.random.rand()
Out[8]: 0.47454906155883114
x = tf.placeholder("float")
y = tf.placeholder("float")
m = tf.Variable([1.0], name="m-slope-coefficient") # initial values ... for now they don't matter much
b = tf.Variable([1.0], name="b-intercept")
y_model = tf.multiply(x, m) + b
error = tf.square(y - y_model)
train_op = tf.train.GradientDescentOptimizer(0.01).minimize(error)
model = tf.global_variables_initializer()
with tf.Session() as session:
session.run(model)
for i in range(10):
x_value = np.random.rand()
y_value = x_value * 2 + 6 # we know these params, but we're making TF learn them
session.run(train_op, feed_dict={x: x_value, y: y_value})
out = session.run([m, b])
print(out)
print("Model: {r:.3f}x + {s:.3f}".format(r=out[0][0], s=out[1][0]))
[array([ 1.41145968], dtype=float32), array([ 1.97268069], dtype=float32)] Model: 1.411x + 1.973
That's pretty terrible :)
Try two experiments. Change the number of iterations the optimizer runs, and -- independently -- try changing the learning rate (that's the number we passed to GradientDescentOptimizer)
See what happens with different values.
These are scalars. Where do the tensors come in?
Using matrices allows us to represent (and, with the right hardware, compute) the data-weight dot products for lots of data vectors (a mini batch) and lots of weight vectors (neurons) at the same time.
Tensors are useful because some of our data "vectors" are really multidimensional -- for example, with a color image we may want to preserve height, width, and color planes. We can hold multiple color images, with their shapes, in a 4-D (or 4 "axis") tensor.
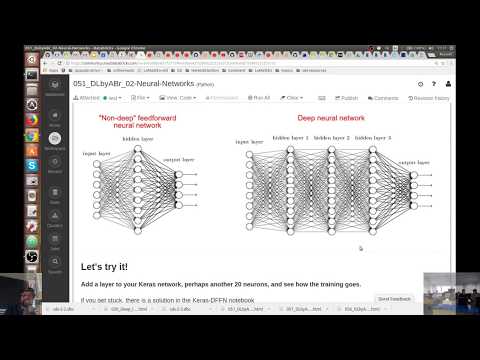
Let's also make the connection from Keras down to Tensorflow.
We used a Keras class called Dense, which represents a "fully-connected" layer of -- in this case -- linear perceptrons. Let's look at the source code to that, just to see that there's no mystery.
https://github.com/fchollet/keras/blob/master/keras/layers/core.py
It calls down to the "back end" by calling output = K.dot(inputs, self.kernel) where kernel means this layer's weights.
K represents the pluggable backend wrapper. You can trace K.dot on Tensorflow by looking at
https://github.com/fchollet/keras/blob/master/keras/backend/tensorflow\_backend.py
Look for def dot(x, y): and look right toward the end of the method. The math is done by calling tf.matmul(x, y)
What else helps Tensorflow (and other frameworks) run fast?
- A fast, simple mechanism for calculating all of the partial derivatives we need, called reverse-mode autodifferentiation
- Implementations of low-level operations in optimized CPU code (e.g., C++, MKL) and GPU code (CUDA/CuDNN/HLSL)
- Support for distributed parallel training, although parallelizing deep learning is non-trivial ... not automagic like with, e.g., Apache Spark
That is the essence of TensorFlow!
There are three principal directions to explore further:
Working with tensors instead of scalars: this is not intellectually difficult, but takes some practice to wrangle the shaping and re-shaping of tensors. If you get the shape of a tensor wrong, your script will blow up. Just takes practice.
Building more complex models. You can write these yourself using lower level "Ops" -- like matrix multiply -- or using higher level classes like
tf.layers.denseUse the source, Luke!Operations and integration ecosystem: as TensorFlow has matured, it is easier to integrate additional tools and solve the peripheral problems:
- TensorBoard for visualizing training
- tfdbg command-line debugger
- Distributed TensorFlow for clustered training
- GPU integration
- Feeding large datasets from external files
- Tensorflow Serving for serving models (i.e., using an existing model to predict on new incoming data)