SDS-2.2, Scalable Data Science
Archived YouTube video of this live unedited lab-lecture:
Distributed Vertex Programming using GraphX
This is an augmentation of http://go.databricks.com/hubfs/notebooks/3-GraphFrames-User-Guide-scala.html
See:
- https://amplab.cs.berkeley.edu/wp-content/uploads/2014/09/graphx.pdf
- https://amplab.github.io/graphx/
- https://spark.apache.org/docs/latest/graphx-programming-guide.html
- https://databricks.com/blog/2016/03/03/introducing-graphframes.html
- https://databricks.com/blog/2016/03/16/on-time-flight-performance-with-spark-graphframes.html
- http://ampcamp.berkeley.edu/big-data-mini-course/graph-analytics-with-graphx.html
And of course the databricks guide: * https://docs.databricks.com/spark/latest/graph-analysis/index.html
GraphFrames User Guide (Scala)
GraphFrames is a package for Apache Spark which provides DataFrame-based Graphs. It provides high-level APIs in Scala, Java, and Python. It aims to provide both the functionality of GraphX and extended functionality taking advantage of Spark DataFrames. This extended functionality includes motif finding, DataFrame-based serialization, and highly expressive graph queries.
The GraphFrames package is available from Spark Packages.
This notebook demonstrates examples from the GraphFrames User Guide.
// we first need to install the library - graphframes as a Spark package - and attach it to our cluster
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
import org.graphframes._
import org.apache.spark.sql._ import org.apache.spark.sql.functions._ import org.graphframes._
Creating GraphFrames
Let us try to create an example social network from the blog: * https://databricks.com/blog/2016/03/03/introducing-graphframes.html.
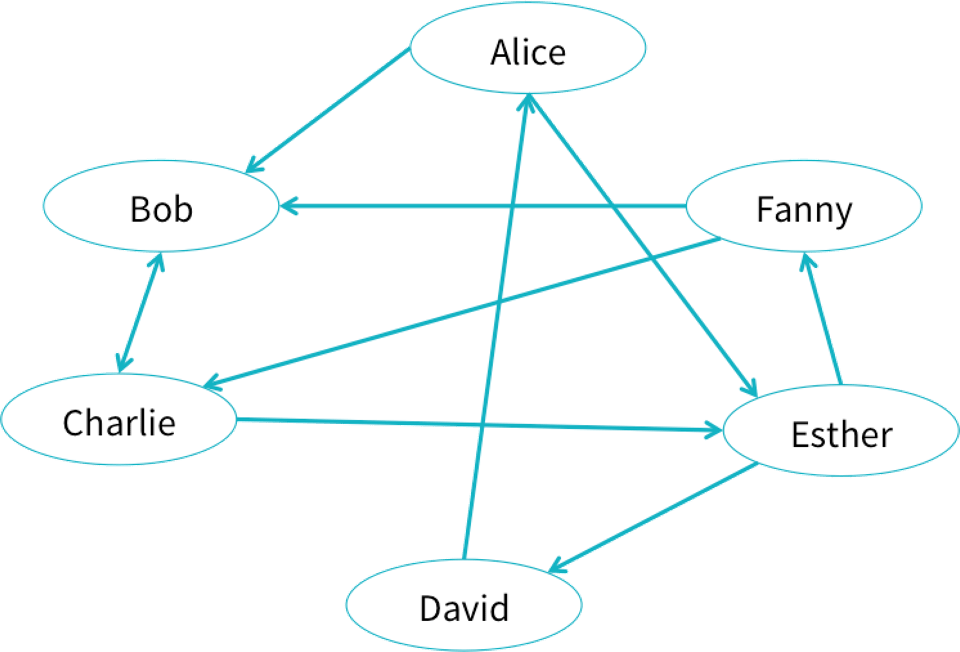
Users can create GraphFrames from vertex and edge DataFrames.
- Vertex DataFrame: A vertex DataFrame should contain a special column named
idwhich specifies unique IDs for each vertex in the graph. - Edge DataFrame: An edge DataFrame should contain two special columns:
src(source vertex ID of edge) anddst(destination vertex ID of edge).
Both DataFrames can have arbitrary other columns. Those columns can represent vertex and edge attributes.
In our example, we can use a GraphFrame can store data or properties associated with each vertex and edge.
In our social network, each user might have an age and name, and each connection might have a relationship type.
Create the vertices and edges
// Vertex DataFrame
val v = sqlContext.createDataFrame(List(
("a", "Alice", 34),
("b", "Bob", 36),
("c", "Charlie", 30),
("d", "David", 29),
("e", "Esther", 32),
("f", "Fanny", 36),
("g", "Gabby", 60)
)).toDF("id", "name", "age")
// Edge DataFrame
val e = sqlContext.createDataFrame(List(
("a", "b", "friend"),
("b", "c", "follow"),
("c", "b", "follow"),
("f", "c", "follow"),
("e", "f", "follow"),
("e", "d", "friend"),
("d", "a", "friend"),
("a", "e", "friend")
)).toDF("src", "dst", "relationship")
v: org.apache.spark.sql.DataFrame = [id: string, name: string ... 1 more field] e: org.apache.spark.sql.DataFrame = [src: string, dst: string ... 1 more field]
Let's create a graph from these vertices and these edges:
val g = GraphFrame(v, e)
g: org.graphframes.GraphFrame = GraphFrame(v:[id: string, name: string ... 1 more field], e:[src: string, dst: string ... 1 more field])
Let's use the d3.graphs to visualise graphs (recall the D3 graphs in wiki-click example).
Warning: classes defined within packages cannot be redefined without a cluster restart. Compilation successful.
d3.graphs.help()
Produces a force-directed graph given a collection of edges of the following form:
case class Edge(src: String, dest: String, count: Long)
Usage:
import d3._
graphs.force(
height = 500,
width = 500,
clicks: Dataset[Edge])
import org.apache.spark.sql.functions.lit // import the lit function in sql
val gE= g.edges.select($"src", $"dst".as("dest"), lit(1L).as("count")) // for us the column count is just an edge incidence
import org.apache.spark.sql.functions.lit gE: org.apache.spark.sql.DataFrame = [src: string, dest: string ... 1 more field]
display(gE)
| src | dest | count |
|---|---|---|
| a | b | 1.0 |
| b | c | 1.0 |
| c | b | 1.0 |
| f | c | 1.0 |
| e | f | 1.0 |
| e | d | 1.0 |
| d | a | 1.0 |
| a | e | 1.0 |
d3.graphs.force(
height = 500,
width = 500,
clicks = gE.as[d3.Edge])
// This example graph also comes with the GraphFrames package.
val g0 = examples.Graphs.friends
g0: org.graphframes.GraphFrame = GraphFrame(v:[id: string, name: string ... 1 more field], e:[src: string, dst: string ... 1 more field])
d3.graphs.force( // let us see g0 now in one cell
height = 500,
width = 500,
clicks = g0.edges.select($"src", $"dst".as("dest"), lit(1L).as("count")).as[d3.Edge])
Basic graph and DataFrame queries
GraphFrames provide several simple graph queries, such as node degree.
Also, since GraphFrames represent graphs as pairs of vertex and edge DataFrames, it is easy to make powerful queries directly on the vertex and edge DataFrames. Those DataFrames are made available as vertices and edges fields in the GraphFrame.
Simple queries are simple
GraphFrames make it easy to express queries over graphs. Since GraphFrame vertices and edges are stored as DataFrames, many queries are just DataFrame (or SQL) queries.
display(g.vertices)
| id | name | age |
|---|---|---|
| a | Alice | 34.0 |
| b | Bob | 36.0 |
| c | Charlie | 30.0 |
| d | David | 29.0 |
| e | Esther | 32.0 |
| f | Fanny | 36.0 |
| g | Gabby | 60.0 |
display(g0.vertices) // this is the same query on the graph loaded as an example from GraphFrame package
| id | name | age |
|---|---|---|
| a | Alice | 34.0 |
| b | Bob | 36.0 |
| c | Charlie | 30.0 |
| d | David | 29.0 |
| e | Esther | 32.0 |
| f | Fanny | 36.0 |
| g | Gabby | 60.0 |
display(g.edges)
| src | dst | relationship |
|---|---|---|
| a | b | friend |
| b | c | follow |
| c | b | follow |
| f | c | follow |
| e | f | follow |
| e | d | friend |
| d | a | friend |
| a | e | friend |
The incoming degree of the vertices:
display(g.inDegrees)
| id | inDegree |
|---|---|
| f | 1.0 |
| e | 1.0 |
| d | 1.0 |
| c | 2.0 |
| b | 2.0 |
| a | 1.0 |
The outgoing degree of the vertices:
display(g.outDegrees)
| id | outDegree |
|---|---|
| f | 1.0 |
| e | 2.0 |
| d | 1.0 |
| c | 1.0 |
| b | 1.0 |
| a | 2.0 |
The degree of the vertices:
display(g.degrees)
| id | degree |
|---|---|
| f | 2.0 |
| e | 3.0 |
| d | 2.0 |
| c | 3.0 |
| b | 3.0 |
| a | 3.0 |
You can run queries directly on the vertices DataFrame. For example, we can find the age of the youngest person in the graph:
val youngest = g.vertices.groupBy().min("age")
display(youngest)
| min(age) |
|---|
| 29.0 |
Likewise, you can run queries on the edges DataFrame.
For example, let us count the number of 'follow' relationships in the graph:
val numFollows = g.edges.filter("relationship = 'follow'").count()
numFollows: Long = 4
Motif finding
More complex relationships involving edges and vertices can be built using motifs.
The following cell finds the pairs of vertices with edges in both directions between them.
The result is a dataframe, in which the column names are given by the motif keys.
Check out the GraphFrame User Guide for more details on the API.
// Search for pairs of vertices with edges in both directions between them, i.e., find undirected or bidirected edges.
val motifs = g.find("(a)-[e1]->(b); (b)-[e2]->(a)")
display(motifs)
Since the result is a DataFrame, more complex queries can be built on top of the motif.
Let us find all the reciprocal relationships in which one person is older than 30:
val filtered = motifs.filter("b.age > 30")
display(filtered)
You Try!
//Search for all "directed triangles" or triplets of vertices: a,b,c with edges: a->b, b->c and c->a
//uncomment the next 2 lines and replace the "..." below
val motifs3 = g.find("(a)-[e1]->(b); (b)-[e2]->(c); (c)-[e3]->(a) ")
display(motifs3)
Stateful queries
Many motif queries are stateless and simple to express, as in the examples above. The next examples demonstrate more complex queries which carry state along a path in the motif. These queries can be expressed by combining GraphFrame motif finding with filters on the result, where the filters use sequence operations to construct a series of DataFrame Columns.
For example, suppose one wishes to identify a chain of 4 vertices with some property defined by a sequence of functions. That is, among chains of 4 vertices a->b->c->d, identify the subset of chains matching this complex filter:
- Initialize state on path.
- Update state based on vertex a.
- Update state based on vertex b.
- Etc. for c and d.
- If final state matches some condition, then the chain is accepted by the filter.
The below code snippets demonstrate this process, where we identify chains of 4 vertices such that at least 2 of the 3 edges are friend relationships. In this example, the state is the current count of friend edges; in general, it could be any DataFrame Column.
// Find chains of 4 vertices.
val chain4 = g.find("(a)-[ab]->(b); (b)-[bc]->(c); (c)-[cd]->(d)")
// Query on sequence, with state (cnt)
// (a) Define method for updating state given the next element of the motif.
def sumFriends(cnt: Column, relationship: Column): Column = {
when(relationship === "friend", cnt + 1).otherwise(cnt)
}
// (b) Use sequence operation to apply method to sequence of elements in motif.
// In this case, the elements are the 3 edges.
val condition = Seq("ab", "bc", "cd").
foldLeft(lit(0))((cnt, e) => sumFriends(cnt, col(e)("relationship")))
// (c) Apply filter to DataFrame.
val chainWith2Friends2 = chain4.where(condition >= 2)
display(chainWith2Friends2)
Bold idea!
Can you think of a way to use stateful queries in social media networks to find perpetrators of hate-speech online who are possibly worthy of an investigation by domain experts, say in the intelligence or security domain, for potential prosecution on charges of having incited another person to cause physical violence... This is a real problem today!
An idea for a product?
Subgraphs
Subgraphs are built by filtering a subset of edges and vertices. For example, the following subgraph only contains people who are friends and who are more than 30 years old.
// Select subgraph of users older than 30, and edges of type "friend"
val v2 = g.vertices.filter("age > 30")
val e2 = g.edges.filter("relationship = 'friend'")
val g2 = GraphFrame(v2, e2)
v2: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [id: string, name: string ... 1 more field] e2: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [src: string, dst: string ... 1 more field] g2: org.graphframes.GraphFrame = GraphFrame(v:[id: string, name: string ... 1 more field], e:[src: string, dst: string ... 1 more field])
display(g2.vertices)
| id | name | age |
|---|---|---|
| a | Alice | 34.0 |
| b | Bob | 36.0 |
| e | Esther | 32.0 |
| f | Fanny | 36.0 |
| g | Gabby | 60.0 |
display(g2.edges)
| src | dst | relationship |
|---|---|---|
| a | b | friend |
| e | d | friend |
| d | a | friend |
| a | e | friend |
d3.graphs.force( // let us see g2 now in one cell
height = 500,
width = 500,
clicks = g2.edges.select($"src", $"dst".as("dest"), lit(1L).as("count")).as[d3.Edge])
Complex triplet filters
The following example shows how to select a subgraph based upon triplet filters which operate on:
- an edge and
- its src and
- dst vertices.
This example could be extended to go beyond triplets by using more complex motifs.
// Select subgraph based on edges "e" of type "follow"
// pointing from a younger user "a" to an older user "b".
val paths = g.find("(a)-[e]->(b)")
.filter("e.relationship = 'follow'")
.filter("a.age < b.age")
// "paths" contains vertex info. Extract the edges.
val e2 = paths.select("e.src", "e.dst", "e.relationship")
// In Spark 1.5+, the user may simplify this call:
// val e2 = paths.select("e.*")
// Construct the subgraph
val g2 = GraphFrame(g.vertices, e2)
paths: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [a: struct<id: string, name: string ... 1 more field>, e: struct<src: string, dst: string ... 1 more field> ... 1 more field] e2: org.apache.spark.sql.DataFrame = [src: string, dst: string ... 1 more field] g2: org.graphframes.GraphFrame = GraphFrame(v:[id: string, name: string ... 1 more field], e:[src: string, dst: string ... 1 more field])
display(g2.vertices)
| id | name | age |
|---|---|---|
| a | Alice | 34.0 |
| b | Bob | 36.0 |
| c | Charlie | 30.0 |
| d | David | 29.0 |
| e | Esther | 32.0 |
| f | Fanny | 36.0 |
| g | Gabby | 60.0 |
display(g2.edges)
| src | dst | relationship |
|---|---|---|
| c | b | follow |
| e | f | follow |
Standard graph algorithms
GraphFrames comes with a number of standard graph algorithms built in:
- Breadth-first search (BFS)
- Connected components
- Strongly connected components
- Label Propagation Algorithm (LPA)
- PageRank
- Shortest paths
- Triangle count
Breadth-first search (BFS)
Read
Search from "Esther" for users of age < 32.
// Search from "Esther" for users of age <= 32.
val paths: DataFrame = g.bfs.fromExpr("name = 'Esther'").toExpr("age < 32").run()
display(paths)
val paths: DataFrame = g.bfs.fromExpr("name = 'Esther' OR name = 'Bob'").toExpr("age < 32").run()
display(paths)
The search may also be limited by edge filters and maximum path lengths.
val filteredPaths = g.bfs.fromExpr("name = 'Esther'").toExpr("age < 32")
.edgeFilter("relationship != 'friend'")
.maxPathLength(3)
.run()
display(filteredPaths)
Connected components
Compute the connected component membership of each vertex and return a graph with each vertex assigned a component ID.
READ http://graphframes.github.io/user-guide.html#connected-components.
From http://graphframes.github.io/user-guide.html#connected-components:-
NOTE: With GraphFrames 0.3.0 and later releases, the default Connected Components algorithm requires setting a Spark checkpoint directory. Users can revert to the old algorithm using .setAlgorithm("graphx").
See https://jaceklaskowski.gitbooks.io/mastering-apache-spark/spark-rdd-checkpointing.html to see why we need to check-point to keep the RDD lineage DAGs from growing out of control.
sc.setCheckpointDir("/_checkpoint") // just a directory in distributed file system
val result = g.connectedComponents.run()
display(result)
| id | name | age | component |
|---|---|---|---|
| a | Alice | 34.0 | 4.12316860416e11 |
| b | Bob | 36.0 | 4.12316860416e11 |
| c | Charlie | 30.0 | 4.12316860416e11 |
| d | David | 29.0 | 4.12316860416e11 |
| e | Esther | 32.0 | 4.12316860416e11 |
| f | Fanny | 36.0 | 4.12316860416e11 |
| g | Gabby | 60.0 | 1.46028888064e11 |
Fun Exercise: Try to modify the d3.graph function to allow a visualisation of a given Sequence of component ids in the above result.
Strongly connected components
Compute the strongly connected component (SCC) of each vertex and return a graph with each vertex assigned to the SCC containing that vertex.
READ http://graphframes.github.io/user-guide.html#strongly-connected-components.
val result = g.stronglyConnectedComponents.maxIter(10).run()
display(result.orderBy("component"))
| id | name | age | component |
|---|---|---|---|
| e | Esther | 32.0 | 0.0 |
| d | David | 29.0 | 0.0 |
| a | Alice | 34.0 | 0.0 |
| b | Bob | 36.0 | 2.0 |
| c | Charlie | 30.0 | 2.0 |
| f | Fanny | 36.0 | 5.0 |
| g | Gabby | 60.0 | 7.0 |
Label propagation
Run static Label Propagation Algorithm for detecting communities in networks.
Each node in the network is initially assigned to its own community. At every superstep, nodes send their community affiliation to all neighbors and update their state to the mode community affiliation of incoming messages.
LPA is a standard community detection algorithm for graphs. It is very inexpensive computationally, although
- (1) convergence is not guaranteed and
- (2) one can end up with trivial solutions (all nodes are identified into a single community).
READ: http://graphframes.github.io/user-guide.html#label-propagation-algorithm-lpa.
val result = g.labelPropagation.maxIter(5).run()
display(result.orderBy("label"))
| id | name | age | label |
|---|---|---|---|
| g | Gabby | 60.0 | 1.46028888064e11 |
| b | Bob | 36.0 | 1.047972020224e12 |
| d | David | 29.0 | 1.047972020224e12 |
| f | Fanny | 36.0 | 1.047972020224e12 |
| a | Alice | 34.0 | 1.382979469312e12 |
| c | Charlie | 30.0 | 1.382979469312e12 |
| e | Esther | 32.0 | 1.382979469312e12 |
PageRank
Identify important vertices in a graph based on connections.
READ: http://graphframes.github.io/user-guide.html#pagerank.
// Run PageRank until convergence to tolerance "tol".
val results = g.pageRank.resetProbability(0.15).tol(0.01).run()
display(results.vertices)
| id | name | age | pagerank |
|---|---|---|---|
| b | Bob | 36.0 | 2.2131428039184433 |
| e | Esther | 32.0 | 0.309074279296875 |
| a | Alice | 34.0 | 0.37429242187499995 |
| f | Fanny | 36.0 | 0.27366105468749996 |
| g | Gabby | 60.0 | 0.15 |
| d | David | 29.0 | 0.27366105468749996 |
| c | Charlie | 30.0 | 2.240080617201845 |
display(results.edges)
| src | dst | relationship | weight |
|---|---|---|---|
| a | b | friend | 0.5 |
| b | c | follow | 1.0 |
| e | f | follow | 0.5 |
| e | d | friend | 0.5 |
| c | b | follow | 1.0 |
| a | e | friend | 0.5 |
| f | c | follow | 1.0 |
| d | a | friend | 1.0 |
// Run PageRank for a fixed number of iterations.
val results2 = g.pageRank.resetProbability(0.15).maxIter(10).run()
display(results2.vertices)
| id | name | age | pagerank |
|---|---|---|---|
| b | Bob | 36.0 | 1.842259190054981 |
| e | Esther | 32.0 | 0.31616362485373634 |
| a | Alice | 34.0 | 0.39143465933514154 |
| f | Fanny | 36.0 | 0.28427148788098855 |
| g | Gabby | 60.0 | 0.15 |
| d | David | 29.0 | 0.28427148788098855 |
| c | Charlie | 30.0 | 1.877540087856477 |
// Run PageRank personalized for vertex "a"
val results3 = g.pageRank.resetProbability(0.15).maxIter(10).sourceId("a").run()
display(results3.vertices)
| id | name | age | pagerank |
|---|---|---|---|
| b | Bob | 36.0 | 0.2699384803126761 |
| e | Esther | 32.0 | 7.527103448140514e-2 |
| a | Alice | 34.0 | 0.1771083164268356 |
| f | Fanny | 36.0 | 3.18921369727478e-2 |
| g | Gabby | 60.0 | 0.0 |
| d | David | 29.0 | 3.18921369727478e-2 |
| c | Charlie | 30.0 | 0.24655465114397318 |
Shortest paths
Computes shortest paths to the given set of landmark vertices, where landmarks are specified by vertex ID.
READ http://graphframes.github.io/user-guide.html#shortest-paths.
val paths = g.shortestPaths.landmarks(Seq("a", "d")).run()
display(paths)
Triangle count
Computes the number of triangles passing through each vertex.
See http://graphframes.github.io/user-guide.html#triangle-count
val results = g.triangleCount.run()
display(results)
| count | id | name | age |
|---|---|---|---|
| 0.0 | g | Gabby | 60.0 |
| 0.0 | f | Fanny | 36.0 |
| 1.0 | e | Esther | 32.0 |
| 1.0 | d | David | 29.0 |
| 0.0 | c | Charlie | 30.0 |
| 0.0 | b | Bob | 36.0 |
| 1.0 | a | Alice | 34.0 |
There is a lot more... dig into the docs to find out about belief propogation algorithm now!
See http://graphframes.github.io/user-guide.html#message-passing-via-aggregatemessages