SDS-2.2, Scalable Data Science
Supervised Clustering with Decision Trees
Visual Introduction to decision trees and application to hand-written digit recognition
SOURCE: This is just a couple of decorations on a notebook published in databricks community edition in 2016.
Archived YouTube video of this live unedited lab-lecture:
Decision Trees for handwritten digit recognition
This notebook demonstrates learning a Decision Tree using Spark's distributed implementation. It gives the reader a better understanding of some critical hyperparameters for the tree learning algorithm, using examples to demonstrate how tuning the hyperparameters can improve accuracy.
Background: To learn more about Decision Trees, check out the resources at the end of this notebook. The visual description of ML and Decision Trees provides nice intuition helpful to understand this notebook, and Wikipedia gives lots of details.
Data: We use the classic MNIST handwritten digit recognition dataset. It is from LeCun et al. (1998) and may be found under "mnist" at the LibSVM dataset page.
Goal: Our goal for our data is to learn how to recognize digits (0 - 9) from images of handwriting. However, we will focus on understanding trees, not on this particular learning problem.
Takeaways: Decision Trees take several hyperparameters which can affect the accuracy of the learned model. There is no one "best" setting for these for all datasets. To get the optimal accuracy, we need to tune these hyperparameters based on our data.
Let's Build Intuition for Learning with Decision Trees
- Right-click and open the following link in a new Tab:
- The visual description of ML and Decision Trees which was nominated for a NSF Vizzie award.
Load MNIST training and test datasets
Our datasets are vectors of pixels representing images of handwritten digits. For example:


These datasets are stored in the popular LibSVM dataset format. We will load them using MLlib's LibSVM dataset reader utility.
//-----------------------------------------------------------------------------------------------------------------
// using RDD-based MLlib - ok for Spark 1.x
// MLUtils.loadLibSVMFile returns an RDD.
//import org.apache.spark.mllib.util.MLUtils
//val trainingRDD = MLUtils.loadLibSVMFile(sc, "/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt")
//val testRDD = MLUtils.loadLibSVMFile(sc, "/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt")
// We convert the RDDs to DataFrames to use with ML Pipelines.
//val training = trainingRDD.toDF()
//val test = testRDD.toDF()
// Note: In Spark 1.6 and later versions, Spark SQL has a LibSVM data source. The above lines can be simplified to:
//// val training = sqlContext.read.format("libsvm").load("/mnt/mllib/mnist-digits-csv/mnist-digits-train.txt")
//// val test = sqlContext.read.format("libsvm").load("/mnt/mllib/mnist-digits-csv/mnist-digits-test.txt")
//-----------------------------------------------------------------------------------------------------------------
val training = spark.read.format("libsvm")
.option("numFeatures", "780")
.load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt")
val test = spark.read.format("libsvm")
.option("numFeatures", "780")
.load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt")
// Cache data for multiple uses.
training.cache()
test.cache()
println(s"We have ${training.count} training images and ${test.count} test images.")
We have 60000 training images and 10000 test images. training: org.apache.spark.sql.DataFrame = [label: double, features: vector] test: org.apache.spark.sql.DataFrame = [label: double, features: vector]
Display our data. Each image has the true label (the label column) and a vector of features which represent pixel intensities (see below for details of what is in training).
training.printSchema()
root |-- label: double (nullable = true) |-- features: vector (nullable = true)
training.show(3,true) // replace 'true' by 'false' to see the whole row hidden by '...'
+-----+--------------------+ |label| features| +-----+--------------------+ | 5.0|(780,[152,153,154...| | 0.0|(780,[127,128,129...| | 4.0|(780,[160,161,162...| +-----+--------------------+ only showing top 3 rows
display(training) // this is databricks-specific for interactive visual convenience
The pixel intensities are represented in features as a sparse vector, for example the first observation, as seen in row 1 of the output to display(training) or training.show(2,false) above, has label as 5, i.e. the hand-written image is for the number 5. And this hand-written image is the following sparse vector (just click the triangle to the left of the feature in first row to see the following):
type: 0
size: 780
indices: [152,153,155,...,682,683]
values: [3, 18, 18,18,126,...,132,16]
Here,
type: 0says we have a sparse vector that only represents non-zero entries (as opposed to a dense vector where every entry is represented).size: 780says the vector has 780 indices in total- these indices from 0,...,779 are a unidimensional indexing of the two-dimensional array of pixels in the image
indices: [152,153,155,...,682,683]are the indices from the[0,1,...,779]possible indices with non-zero values- a value is an integer encoding the gray-level at the pixel index
values: [3, 18, 18,18,126,...,132,16]are the actual gray level values, for example:- at pixed index
152the gray-level value is3, - at index
153the gray-level value is18, - ..., and finally at
- at index
683the gray-level value is18
- at pixed index
Train a Decision Tree
We begin by training a decision tree using the default settings. Before training, we want to tell the algorithm that the labels are categories 0-9, rather than continuous values. We use the StringIndexer class to do this. We tie this feature preprocessing together with the tree algorithm using a Pipeline. ML Pipelines are tools Spark provides for piecing together Machine Learning algorithms into workflows. To learn more about Pipelines, check out other ML example notebooks in Databricks and the ML Pipelines user guide. Also See mllib-decision-tree.html#basic-algorithm.
See http://spark.apache.org/docs/latest/mllib-decision-tree.html#basic-algorithm.
See http://spark.apache.org/docs/latest/ml-guide.html#main-concepts-in-pipelines.
// Import the ML algorithms we will use.
import org.apache.spark.ml.classification.{DecisionTreeClassifier, DecisionTreeClassificationModel}
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.classification.{DecisionTreeClassifier, DecisionTreeClassificationModel} import org.apache.spark.ml.feature.StringIndexer import org.apache.spark.ml.Pipeline
// StringIndexer: Read input column "label" (digits) and annotate them as categorical values.
val indexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
// DecisionTreeClassifier: Learn to predict column "indexedLabel" using the "features" column.
val dtc = new DecisionTreeClassifier().setLabelCol("indexedLabel")
// Chain indexer + dtc together into a single ML Pipeline.
val pipeline = new Pipeline().setStages(Array(indexer, dtc))
indexer: org.apache.spark.ml.feature.StringIndexer = strIdx_0610548abbdf dtc: org.apache.spark.ml.classification.DecisionTreeClassifier = dtc_fc540a374780 pipeline: org.apache.spark.ml.Pipeline = pipeline_6fafc07ce7b9
Now, let's fit a model to our data.
val model = pipeline.fit(training)
model: org.apache.spark.ml.PipelineModel = pipeline_6fafc07ce7b9
We can inspect the learned tree by displaying it using Databricks ML visualization. (Visualization is available for several but not all models.)
// The tree is the last stage of the Pipeline. Display it!
val tree = model.stages.last.asInstanceOf[DecisionTreeClassificationModel]
display(tree)
| treeNode |
|---|
| {"index":31,"featureType":"continuous","prediction":null,"threshold":128.0,"categories":null,"feature":350,"overflow":false} |
| {"index":15,"featureType":"continuous","prediction":null,"threshold":0.0,"categories":null,"feature":568,"overflow":false} |
| {"index":7,"featureType":"continuous","prediction":null,"threshold":0.0,"categories":null,"feature":430,"overflow":false} |
| {"index":3,"featureType":"continuous","prediction":null,"threshold":2.0,"categories":null,"feature":405,"overflow":false} |
| {"index":1,"featureType":"continuous","prediction":null,"threshold":0.0,"categories":null,"feature":484,"overflow":false} |
| {"index":0,"featureType":null,"prediction":1.0,"threshold":null,"categories":null,"feature":null,"overflow":false} |
| {"index":2,"featureType":null,"prediction":4.0,"threshold":null,"categories":null,"feature":null,"overflow":false} |
| {"index":5,"featureType":"continuous","prediction":null,"threshold":14.0,"categories":null,"feature":516,"overflow":false} |
| {"index":4,"featureType":null,"prediction":9.0,"threshold":null,"categories":null,"feature":null,"overflow":false} |
| {"index":6,"featureType":null,"prediction":7.0,"threshold":null,"categories":null,"feature":null,"overflow":false} |
| {"index":11,"featureType":"continuous","prediction":null,"threshold":34.0,"categories":null,"feature":211,"overflow":false} |
| {"index":9,"featureType":"continuous","prediction":null,"threshold":0.0,"categories":null,"feature":98,"overflow":false} |
| {"index":8,"featureType":null,"prediction":8.0,"threshold":null,"categories":null,"feature":null,"overflow":false} |
| {"index":10,"featureType":null,"prediction":6.0,"threshold":null,"categories":null,"feature":null,"overflow":false} |
| {"index":13,"featureType":"continuous","prediction":null,"threshold":0.0,"categories":null,"feature":156,"overflow":false} |
| {"index":12,"featureType":null,"prediction":4.0,"threshold":null,"categories":null,"feature":null,"overflow":false} |
| {"index":14,"featureType":null,"prediction":6.0,"threshold":null,"categories":null,"feature":null,"overflow":false} |
| {"index":23,"featureType":"continuous","prediction":null,"threshold":0.0,"categories":null,"feature":435,"overflow":false} |
| {"index":19,"featureType":"continuous","prediction":null,"threshold":10.0,"categories":null,"feature":489,"overflow":false} |
| {"index":17,"featureType":"continuous","prediction":null,"threshold":2.0,"categories":null,"feature":380,"overflow":false} |
| {"index":16,"featureType":null,"prediction":5.0,"threshold":null,"categories":null,"feature":null,"overflow":false} |
| {"index":18,"featureType":null,"prediction":9.0,"threshold":null,"categories":null,"feature":null,"overflow":false} |
| {"index":21,"featureType":"continuous","prediction":null,"threshold":0.0,"categories":null,"feature":320,"overflow":false} |
| {"index":20,"featureType":null,"prediction":3.0,"threshold":null,"categories":null,"feature":null,"overflow":false} |
| {"index":22,"featureType":null,"prediction":9.0,"threshold":null,"categories":null,"feature":null,"overflow":false} |
| {"index":27,"featureType":"continuous","prediction":null,"threshold":0.0,"categories":null,"feature":346,"overflow":false} |
| {"index":25,"featureType":"continuous","prediction":null,"threshold":89.0,"categories":null,"feature":348,"overflow":false} |
| {"index":24,"featureType":null,"prediction":3.0,"threshold":null,"categories":null,"feature":null,"overflow":false} |
| {"index":26,"featureType":null,"prediction":7.0,"threshold":null,"categories":null,"feature":null,"overflow":false} |
| {"index":29,"featureType":"continuous","prediction":null,"threshold":0.0,"categories":null,"feature":655,"overflow":false} |
Truncated to 30 rows
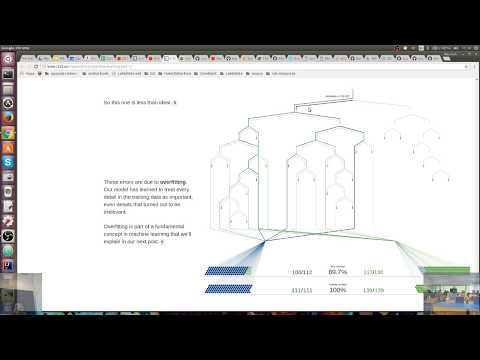
Above, we can see how the tree makes predictions. When classifying a new example, the tree starts at the "root" node (at the top). Each tree node tests a pixel value and goes either left or right. At the bottom "leaf" nodes, the tree predicts a digit as the image's label.
Hyperparameter Tuning
Run the next cell and come back into hyper-parameter tuning for a couple minutes.
Exploring "maxDepth": training trees of different sizes
In this section, we test tuning a single hyperparameter maxDepth, which determines how deep (and large) the tree can be. We will train trees at varying depths and see how it affects the accuracy on our held-out test set.
Note: The next cell can take about 1 minute to run since it is training several trees which get deeper and deeper.
val variedMaxDepthModels = (0 until 8).map { maxDepth =>
// For this setting of maxDepth, learn a decision tree.
dtc.setMaxDepth(maxDepth)
// Create a Pipeline with our feature processing stage (indexer) plus the tree algorithm
val pipeline = new Pipeline().setStages(Array(indexer, dtc))
// Run the ML Pipeline to learn a tree.
pipeline.fit(training)
}
variedMaxDepthModels: scala.collection.immutable.IndexedSeq[org.apache.spark.ml.PipelineModel] = Vector(pipeline_69ede46d1710, pipeline_d266ac2104e8, pipeline_56cd339e4e3b, pipeline_537b78b25cae, pipeline_78bbe3bd95e7, pipeline_00b13cbae30c, pipeline_26bb7880555e, pipeline_805019a1d27f)
We will use the default metric to evaluate the performance of our classifier:
// Define an evaluation metric. In this case, we will use "accuracy".
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
val evaluator = new MulticlassClassificationEvaluator().setLabelCol("indexedLabel").setMetricName("f1") // default MetricName
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator evaluator: org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator = mcEval_589917d92896
// For each maxDepth setting, make predictions on the test data, and compute the classifier's f1 performance metric.
val f1MetricPerformanceMeasures = (0 until 8).map { maxDepth =>
val model = variedMaxDepthModels(maxDepth)
// Calling transform() on the test set runs the fitted pipeline.
// The learned model makes predictions on each test example.
val predictions = model.transform(test)
// Calling evaluate() on the predictions DataFrame computes our performance metric.
(maxDepth, evaluator.evaluate(predictions))
}.toDF("maxDepth", "f1")
f1MetricPerformanceMeasures: org.apache.spark.sql.DataFrame = [maxDepth: int, f1: double]
We can display our accuracy results and see immediately that deeper, larger trees are more powerful classifiers, achieving higher accuracies.
Note: When you run f1MetricPerformanceMeasures.show(), you will get a table with f1 score getting better (i.e., approaching 1) with depth.
f1MetricPerformanceMeasures.show()
+--------+-------------------+ |maxDepth| f1| +--------+-------------------+ | 0| 0.023138302649304| | 1|0.07684194241456495| | 2|0.21424979609445727| | 3|0.43288417913985733| | 4| 0.5918599114483921| | 5| 0.6799688659857508| | 6| 0.749398509702895| | 7| 0.789045306607664| +--------+-------------------+
Even though deeper trees are more powerful, they are not always better (recall from the SF/NYC city classification from house features at The visual description of ML and Decision Trees). If we kept increasing the depth on a rich enough dataset, training would take longer and longer. We also might risk overfitting (fitting the training data so well that our predictions get worse on test data); it is important to tune parameters based on held-out data to prevent overfitting. This will ensure that the fitted model generalizes well to yet unseen data, i.e. minimizes generalization error in a mathematical statistical sense.
Exploring "maxBins": discretization for efficient distributed computing
This section explores a more expert-level setting maxBins. For efficient distributed training of Decision Trees, Spark and most other libraries discretize (or "bin") continuous features (such as pixel values) into a finite number of values. This is an important step for the distributed implementation, but it introduces a tradeoff: Larger maxBins mean your data will be more accurately represented, but it will also mean more communication (and slower training).
The default value of maxBins generally works, but it is interesting to explore on our handwritten digit dataset. Remember our digit image from above:
It is grayscale. But if we set maxBins = 2, then we are effectively making it a black-and-white image, not grayscale. Will that affect the accuracy of our model? Let's see!
Note: The next cell can take about 35 seconds to run since it trains several trees.
Read the details on maxBins at mllib-decision-tree.html#split-candidates.
See http://spark.apache.org/docs/latest/mllib-decision-tree.html#split-candidates.
dtc.setMaxDepth(6) // Set maxDepth to a reasonable value.
// now try the maxBins "hyper-parameter" which actually acts as a "coarsener"
// mathematical researchers should note that it is a sub-algebra of the finite
// algebra of observable pixel images at the finest resolution available to us
// giving a compression of the image to fewer coarsely represented pixels
val f1MetricPerformanceMeasures = Seq(2, 4, 8, 16, 32).map { case maxBins =>
// For this value of maxBins, learn a tree.
dtc.setMaxBins(maxBins)
val pipeline = new Pipeline().setStages(Array(indexer, dtc))
val model = pipeline.fit(training)
// Make predictions on test data, and compute accuracy.
val predictions = model.transform(test)
(maxBins, evaluator.evaluate(predictions))
}.toDF("maxBins", "f1")
f1MetricPerformanceMeasures: org.apache.spark.sql.DataFrame = [maxBins: int, f1: double]
f1MetricPerformanceMeasures.show()
+-------+------------------+ |maxBins| f1| +-------+------------------+ | 2|0.7426994211960694| | 4|0.7387142919572773| | 8|0.7442687954544963| | 16|0.7444933838771777| | 32| 0.749398509702895| +-------+------------------+
We can see that extreme discretization (black and white) hurts performance as measured by F1-error, but only a bit. Using more bins increases the accuracy (but also makes learning more costly).
What's next?
- Explore: Try out tuning other parameters of trees---or even ensembles like Random Forests or Gradient-Boosted Trees.
- Automated tuning: This type of tuning does not have to be done by hand. (We did it by hand here to show the effects of tuning in detail.) MLlib provides automated tuning functionality via
CrossValidator. Check out the other Databricks ML Pipeline guides or the Spark ML user guide for details.
Resources
If you are interested in learning more on these topics, these resources can get you started:
- Excellent visual description of Machine Learning and Decision Trees
- This gives an intuitive visual explanation of ML, decision trees, overfitting, and more.
- Blog post on MLlib Random Forests and Gradient-Boosted Trees
- Random Forests and Gradient-Boosted Trees combine many trees into more powerful ensemble models. This is the original post describing MLlib's forest and GBT implementations.
- Wikipedia