// Databricks notebook source exported at Tue, 28 Jun 2016 09:33:28 UTC
Scalable Data Science
prepared by Raazesh Sainudiin and Sivanand Sivaram
supported by  and
and

The html source url of this databricks notebook and its recorded Uji  :
:
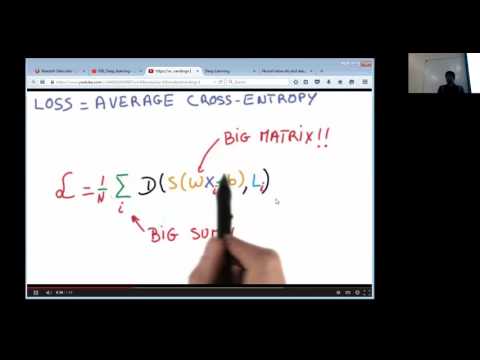
Deep learning with H2O.ai and Spark
- This notebook provides an introduction to the use of Deep Learning algorithms with H2O.ai and Spark
- It shows an example deep learning application written in H2O.ai (Sparkling water) and Spark
Spam classification of SMS data
- Reworked from databricks guide and - https://github.com/h2oai/sparkling-water/blob/master/examples/src/main/scala/org/apache/spark/examples/h2o/HamOrSpamDemo.scala
- Explore the dataset
- Extract features
- Tokenize
- Remove stop words
- Hash
- TF-IDF
- Train a deep learning model
- Predict
Explore the dataset
%fs ls /databricks-datasets/sms_spam_collection/data-001
// Getting the data if you are not on Databricks
/*
import java.net.URL
import java.io.File
import org.apache.commons.io.FileUtils
val SMSDATA_FILE = new File("/tmp/smsData.csv")
FileUtils.copyURLToFile(new URL("https://raw.githubusercontent.com/h2oai/sparkling-water/master/examples/smalldata/smsData.txt"), SMSDATA_FILE)
*/
Exploring the data
sc.textFile("/databricks-datasets/sms_spam_collection/data-001").take(5)
Convert the data to a DataFrame
val data = sqlContext.read
.format("com.databricks.spark.csv")
.option("header", "false")
.option("delimiter", "\t") // Use /t as delimiter
.option("inferSchema", "true")
.load("/databricks-datasets/sms_spam_collection/data-001/smsData.csv")
val df = data.toDF("hamOrSpam", "message")
df.count
display(df)
Featurization
Tokenization
import org.apache.spark.sql.DataFrame
import org.apache.spark.ml.feature.RegexTokenizer
def tokenize(df: DataFrame): DataFrame = {
// Set params for RegexTokenizer
val tokenizer = new RegexTokenizer().
setPattern("[\\W_]+"). // break by white space character(s)
setMinTokenLength(2). // Filter away tokens with length < 2
setToLowercase(true).
setInputCol("message"). // name of the input column
setOutputCol("tokens") // name of the output column
// Tokenize document
tokenizer.transform(df)
}
val tokenized_df = tokenize(df)
Remove stop words
//%sh wget http://ir.dcs.gla.ac.uk/resources/linguistic_utils/stop_words -O /tmp/stopwords # uncomment '//' at the beginning and repeat only if needed again
val stopwords = sc.textFile("/tmp/stopwords").collect() ++ Array(",", ":", ";", "/", "<", ">", "\"", ".", "(", ")", "?", "-", "'", "!", "0", "1")
import org.apache.spark.ml.feature.StopWordsRemover
def removeStopwords(df: DataFrame): DataFrame = {
// Set params for StopWordsRemover
val remover = new StopWordsRemover().
setStopWords(stopwords).
setInputCol("tokens").
setOutputCol("filtered")
remover.transform(df)
}
// Create new DF with Stopwords removed
val filtered_df = removeStopwords(tokenized_df)
Hash - for term frequency
import org.apache.spark.ml.feature.HashingTF
def hasher(df: DataFrame): DataFrame = {
val hashingTF = new HashingTF().
setNumFeatures(1024). // number of features to retain
setInputCol("filtered").
setOutputCol("hashed")
hashingTF.transform(df)
}
val hashed_df = hasher(filtered_df)
hashed_df.printSchema
display(hashed_df.select("hamOrSpam", "message", "hashed").take(10))
TF-IDF (Term Frequency - Inverse Document Frequency) - is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus.
import org.apache.spark.ml.feature.{IDF, IDFModel}
def getIDFModel(df: DataFrame): IDFModel = {
val idf = new IDF().
setMinDocFreq(4).
setInputCol("hashed").
setOutputCol("features")
idf.fit(df)
}
val idfModel = getIDFModel(hashed_df)
val idf_df = idfModel.transform(hashed_df)
display(idf_df.select("hamOrSpam", "message", "hashed", "features").take(10))
Helper function that puts all the featurizers together
import sqlContext.implicits._
def featurizer(message: String): DataFrame = {
val initialDF = sc.parallelize(Seq(message)).
toDF("message").
select(org.apache.spark.sql.functions.lit("?").as("hamOrSpam"), $"message")
val hashedDF = hasher(removeStopwords(tokenize(initialDF)))
idfModel.transform(hashedDF)
}
// Attach H2O library - maven artifact ai.h2o:sparkling-water-examples_2.10:1.6.3
import org.apache.spark.h2o._
// Create H2O Context
val h2oContext = H2OContext.getOrCreate(sc)
// Import h2oContext implicits. This helps converting between RDD, DataFrame and H2OFrame
import h2oContext.implicits._
// Implicitly convert DataFrame to H2O Frame
val table: H2OFrame = idf_df.select("hamOrSpam", "features")
// http://h2o-release.s3.amazonaws.com/h2o/rel-turchin/3/docs-website/h2o-core/javadoc/index.html
table.replace(table.find("hamOrSpam"), table.vec("hamOrSpam").toCategoricalVec).remove()
import water.Key
import hex.FrameSplitter
def split(df: H2OFrame, keys: Seq[String], ratios: Seq[Double]): Array[Frame] = {
val ks = keys.map(Key.make[Frame](_)).toArray
val splitter = new FrameSplitter(df, ratios.toArray, ks, null)
water.H2O.submitTask(splitter)
// return results
splitter.getResult
}
// Split table
val keys = Array[String]("train.hex", "valid.hex")
val ratios = Array[Double](0.8)
val frs = split(table, keys, ratios)
val (train, valid) = (frs(0), frs(1))
table.delete()
What deep learning parameters can we set?
import hex.deeplearning.DeepLearning
import hex.deeplearning.DeepLearningModel
import hex.deeplearning.DeepLearningModel.DeepLearningParameters
import DeepLearningParameters.Activation
val dlParams = new DeepLearningParameters()
dlParams._train = train
dlParams._valid = valid
dlParams._activation = Activation.RectifierWithDropout
dlParams._response_column = 'hamOrSpam
dlParams._epochs = 10
dlParams._l1 = 0.001
dlParams._hidden = Array[Int](200, 200)
// Create a job
val dl = new DeepLearning(dlParams, Key.make("dlModel.hex"))
val dlModel = dl.trainModel.get // trainModel submits a job to H2O Context. get blocks till the job is finished
// get returns a DeepLearningModel
Dropouts
(1:43 seconds):

-- Video Credit: Udacity's deep learning by Arpan Chakraborthy and Vincent Vanhoucke
import water.app.ModelMetricsSupport
import hex.ModelMetricsBinomial
val trainMetrics = ModelMetricsSupport.modelMetrics[ModelMetricsBinomial](dlModel, train)
println(s"Training AUC: ${trainMetrics.auc}")
val validMetrics = ModelMetricsSupport.modelMetrics[ModelMetricsBinomial](dlModel, valid)
println(s"Validation AUC: ${validMetrics.auc}")
import org.apache.spark.ml.feature.IDFModel
import org.apache.spark.sql.DataFrame
def isSpam(msg: String,
hamThreshold: Double = 0.5): Boolean = {
val msgTable: H2OFrame = featurizer(msg)
msgTable.remove(0) // remove first column
val prediction = dlModel.score(msgTable) // score takes a Frame as input and scores the input features identified
println(prediction)
println(prediction.vecs()(1).at(0))
prediction.vecs()(1).at(0) < hamThreshold
}
isSpam("We tried to contact you re your reply to our offer of a Video Handset? 750 anytime any networks mins? UNLIMITED TEXT?")
isSpam("See you at the next Spark meetup")
isSpam("You have won $500,000 from COCA COLA. Contact winner-coco@hotmail.com to claim your prize!")
More examples
Scalable Data Science
prepared by Raazesh Sainudiin and Sivanand Sivaram
supported by
and