// Databricks notebook source exported at Sun, 26 Jun 2016 01:34:53 UTC
Scalable Data Science
Course Project by Akinwande Atanda
supported by  and
and

The html source url of this databricks notebook and its recorded Uji  :
:

Tweet Analytics
Chapter Outline and Objectives
The objectives of this project are:
- Use Apache Spark Streaming API to collect Tweets
- Unfiltered Tweets Collector Set-up
- Filtered Tweets Collector Set-up by Keywords and Hashtags
- Filtered Tweets Collector Set-up by Class
- Extract-Transform-Load (ETL) the collected Tweets:
- Read/Load the Streamed Tweets in batches of RDD
- Read/Load the Streamed Tweets in merged batches of RDDs
- Save the Tweets in Parquet format, convert to Dataframe Table and run SQL queries
- Explore the Streamed Tweets using SQL queries: Filter, Plot and Re-Shape
- Build a featurization dataset for Machine Learning Job
- Explore the binarize classification
- Build a Machine Learning Classification Algorithm Pipeline
- Pipeline without loop
- Pipeline with loop
- Create job to continuously train the algorithm
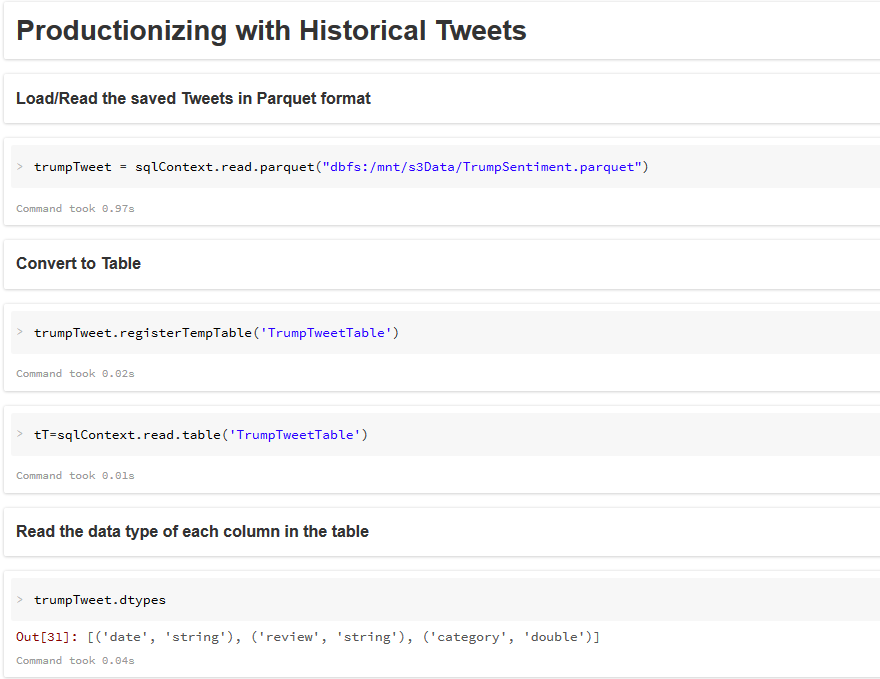
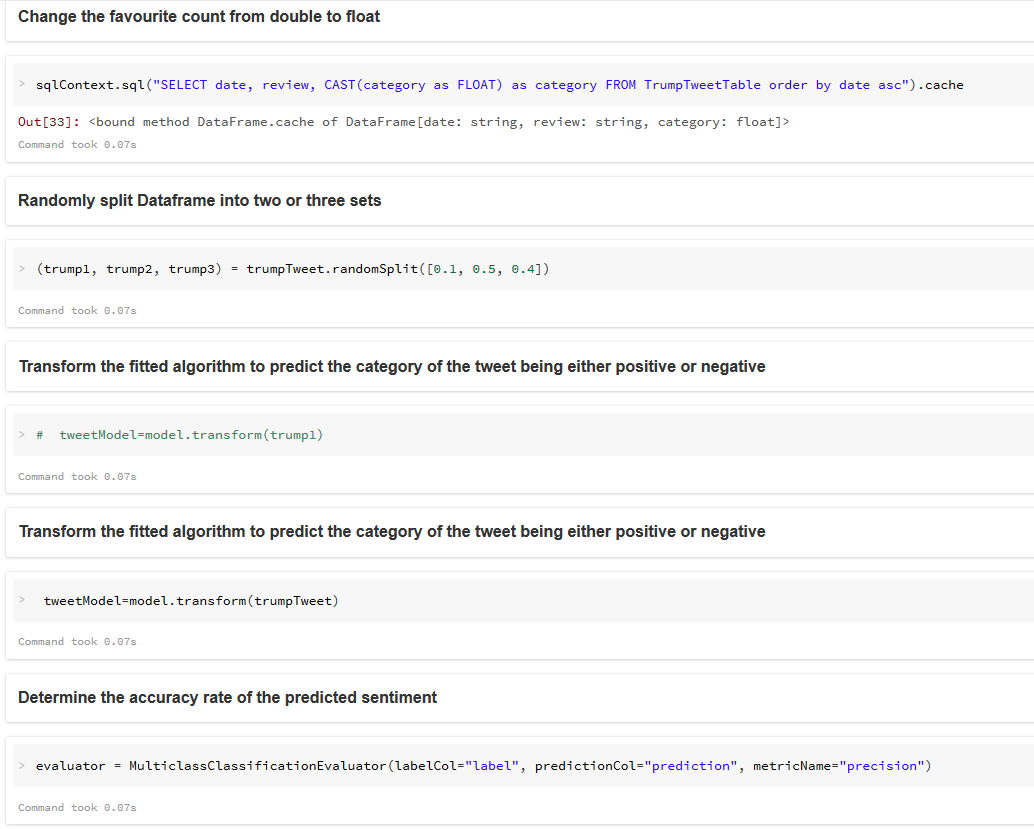
- Productionize the fitted algorithm for Sentiment Analysis
Notebook Execution Order and Description
The chronological order of executing the notebooks for this chapter are listed as follows with corresponidng title:
- Start a Spark Streaming Job
- Execute either of the three collectors depending on the project objective:
- 040_TA01_01_Unfiltered_Tweets_Collector_Set-up
- 041_TA01_02_Filtered_Tweets_Collector_Set-up_by_Keywords_and_Hashtags
- 042_TA01_03_Filtered_Tweets_Collector_Set-up_by_Class
- Process the collected Tweets using the ETL framework
- 043_TA02_ETL_Tweets
- Download, Load and Explore the Features Dataset for the Machine Learning Job
- 044_TA03_01_binary_classification
- Build a Machine Learning Classification Algorithm Pipeline
- Run either of the notebooks depending on the choice of Elastic Parameter values
- 045_TA03_02_binary_classification
- 046_TA03_03_binary_classification_with_Loop
- Productionalize the trainned Algorithm with Historical Tweets
- 047_TA03_04_binary_classification_with_Loop_TweetDataSet
1. Use Apache Spark Streaming API to collect Tweets
- Unfiltered Tweets Collector Set-up
- Filtered Tweets Collector Set-up by Keywords and Hashtags
- Filtered Tweets Collector Set-up by Class
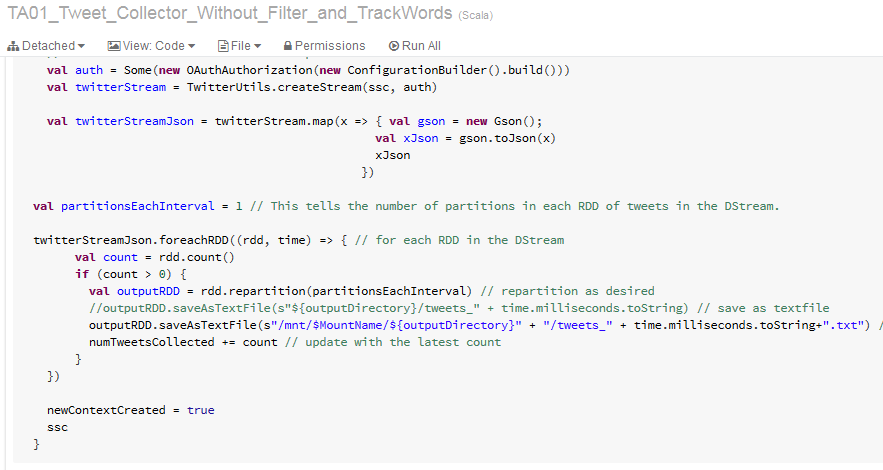
Unfiltered Tweet Collector
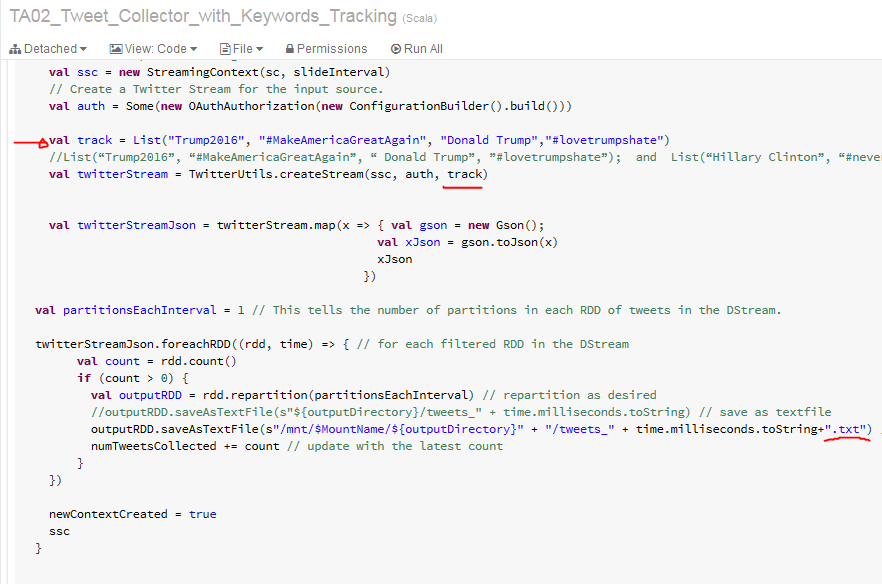
Filtered Tweets Collector Set-up by Keywords and Hashtags
//This allows easy embedding of publicly available information into any other notebook
//when viewing in git-book just ignore this block - you may have to manually chase the URL in frameIt("URL").
//Example usage:
// displayHTML(frameIt("https://en.wikipedia.org/wiki/Latent_Dirichlet_allocation#Topics_in_LDA",250))
def frameIt( u:String, h:Int ) : String = {
"""<iframe
src=""""+ u+""""
width="95%" height="""" + h + """"
sandbox>
<p>
<a href="http://spark.apache.org/docs/latest/index.html">
Fallback link for browsers that, unlikely, don't support frames
</a>
</p>
</iframe>"""
}
displayHTML(frameIt("http://www.wonderoftech.com/best-twitter-tips-followers/", 600))
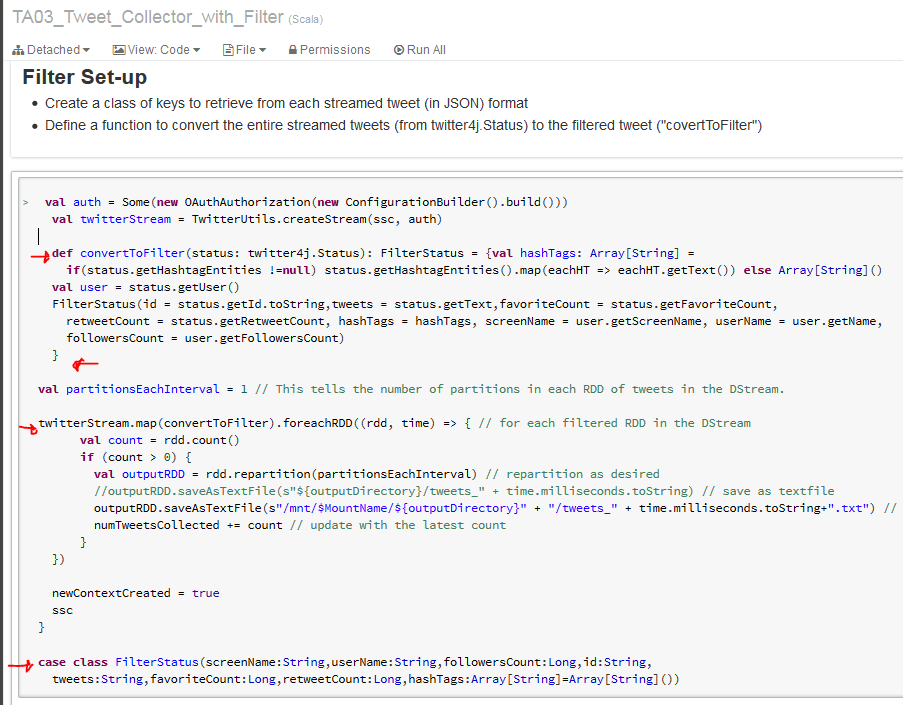
Filtered Tweets Collector Set-up by Class
2. Extract-Transform-Load (ETL) the collected Tweets:
- Read/Load the Streamed Tweets in batches of RDD
- Read/Load the Streamed Tweets in merged batches of RDDs
- Save the Tweets in Parquet format, convert to Dataframe Table and run SQL queries
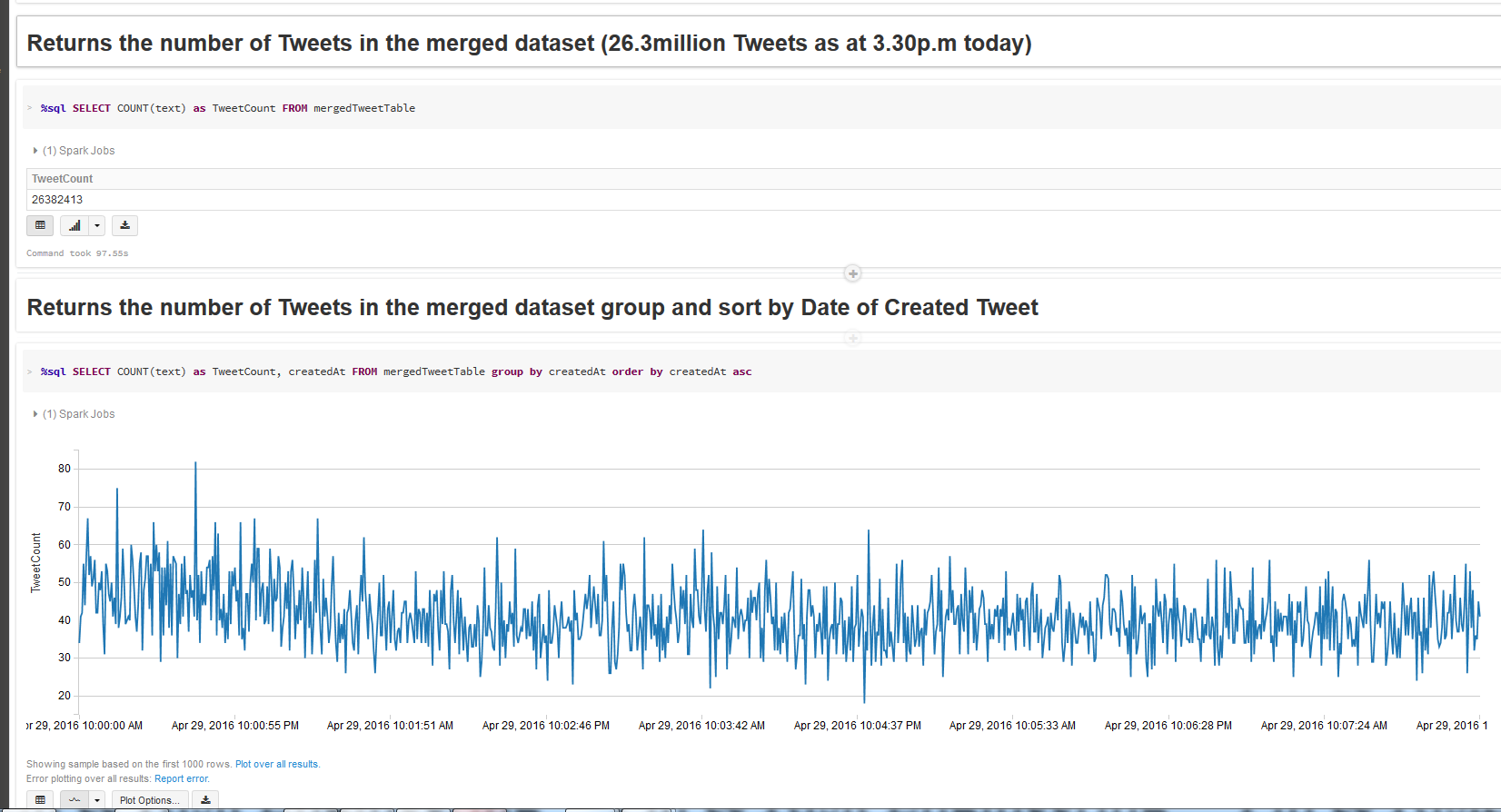
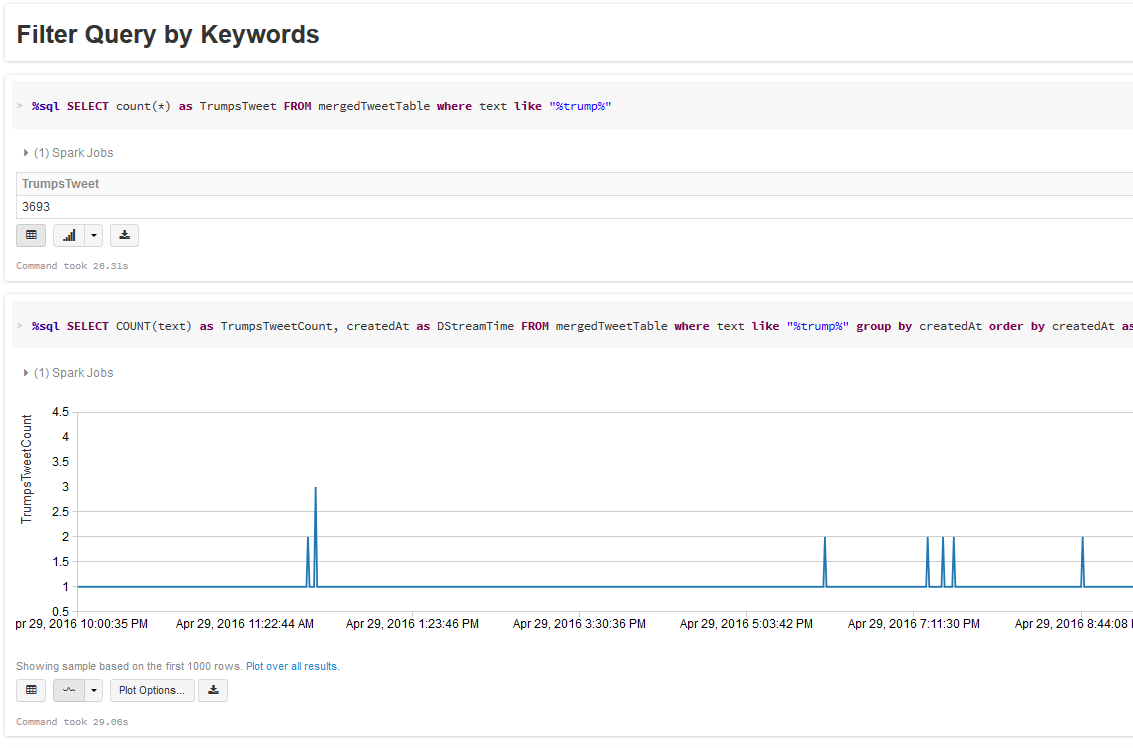
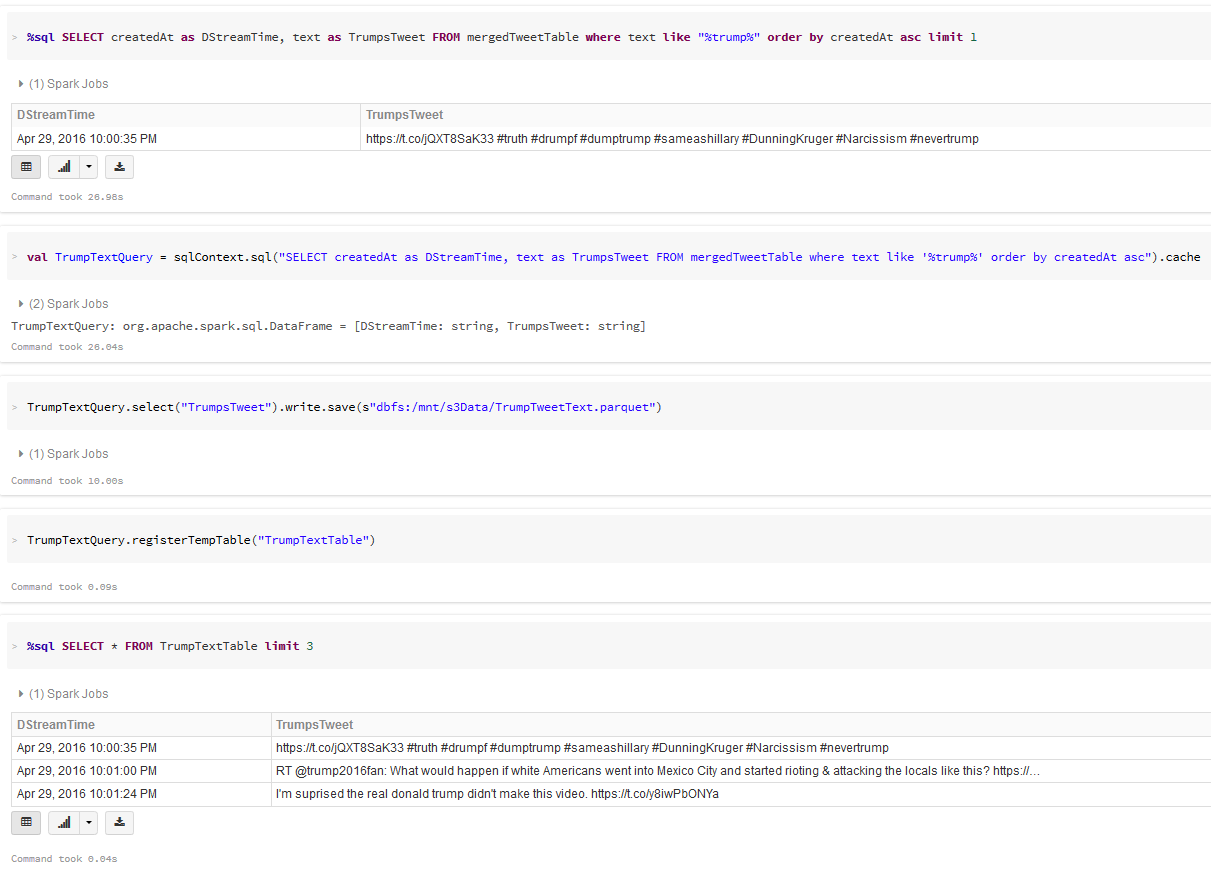
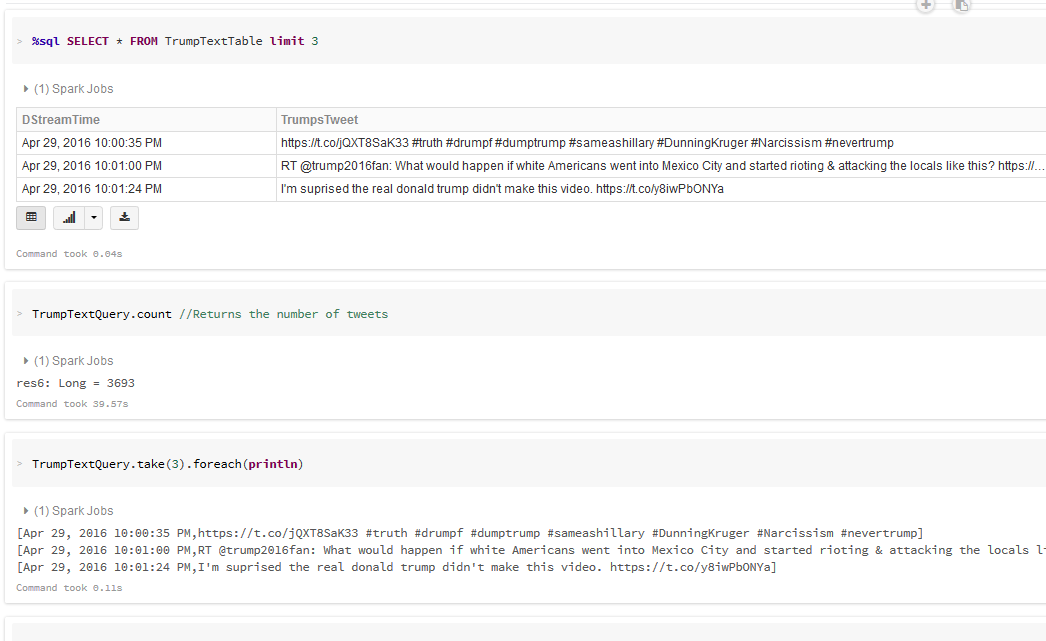
- Explore the Streamed Tweets using SQL queries: Filter, Plot and Re-Shape Extract--Transform--Load: Streamed Tweets
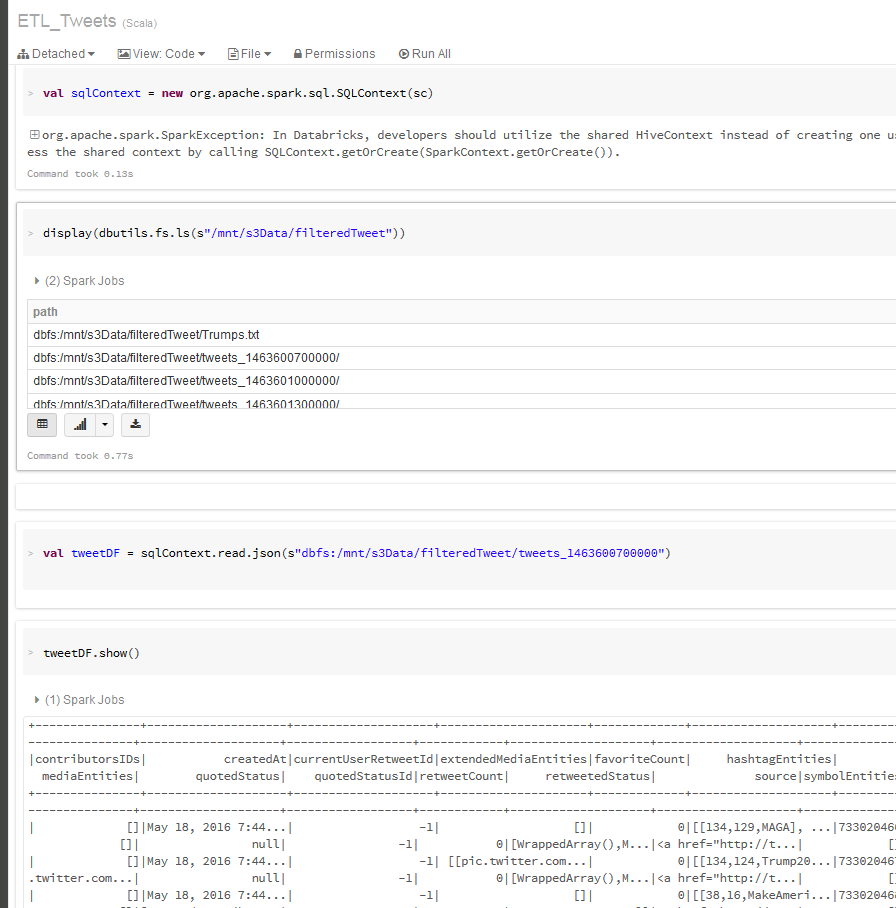
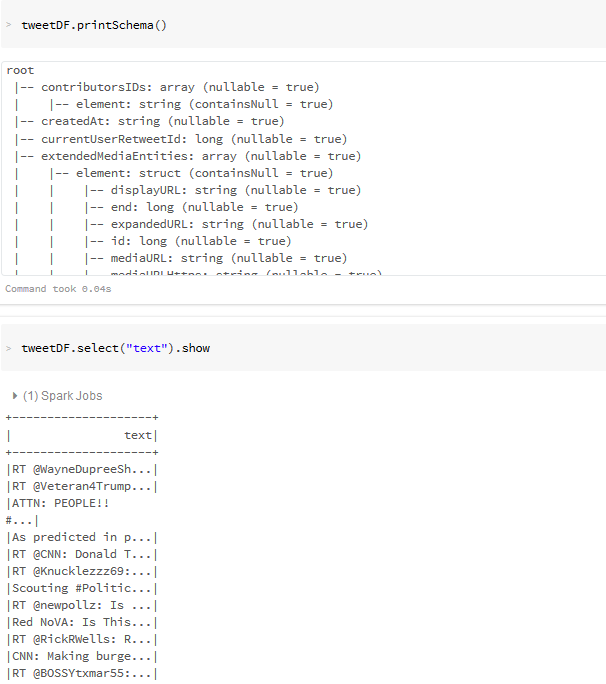
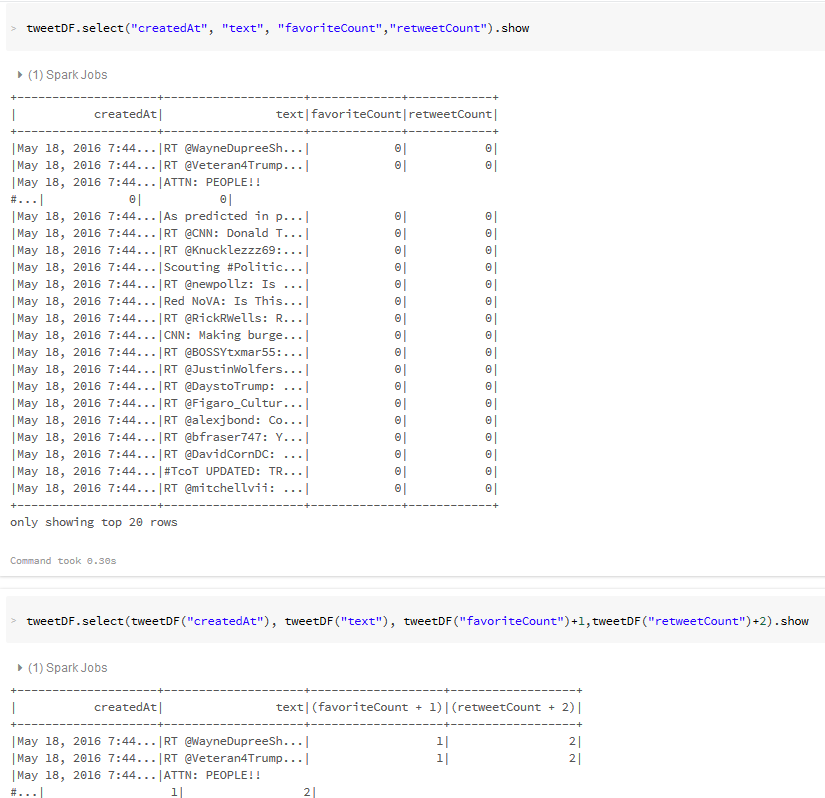
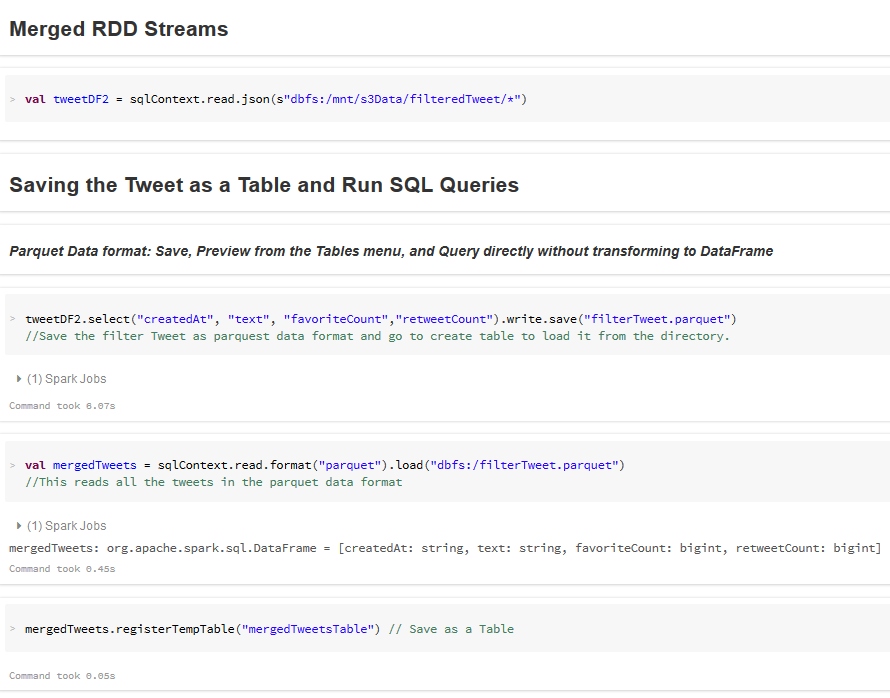
Explore Streamed Tweets: SQL, Filter, Plot and Re-Shape
3. Featurization: Training and Testing Datasets sourced from:
- Amazon Products Reviews;
- Vector of Positive & Negative Words from "Workshop on text analysis" by Neal Caren
- NLTK corpus movie reviews (Postive and Negative Reviews)
- Random Products Reviews (Web Scraped by Sandtex)
- Download the featured dataset "pos_neg_category"
- Upload as a Table and change the data type for the "category" column to double
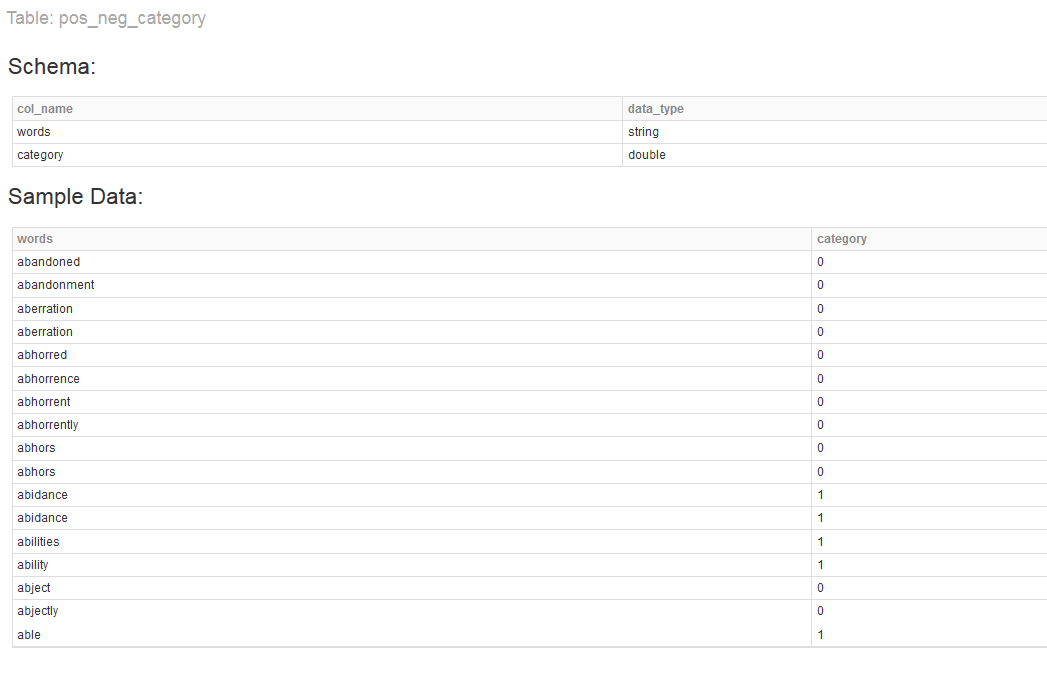
Exploration: Training and Testing Datasets in R
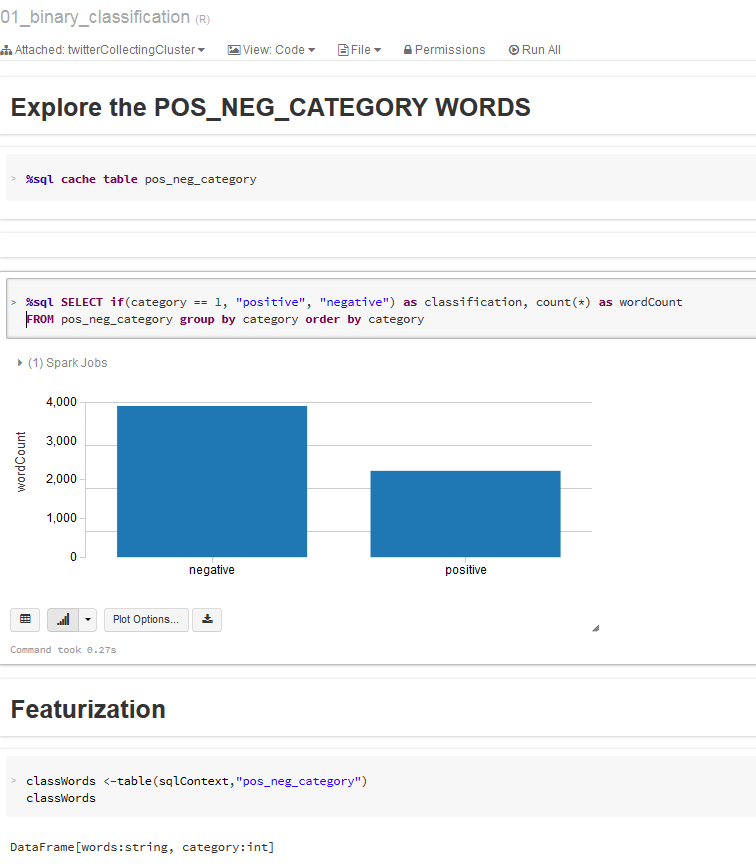
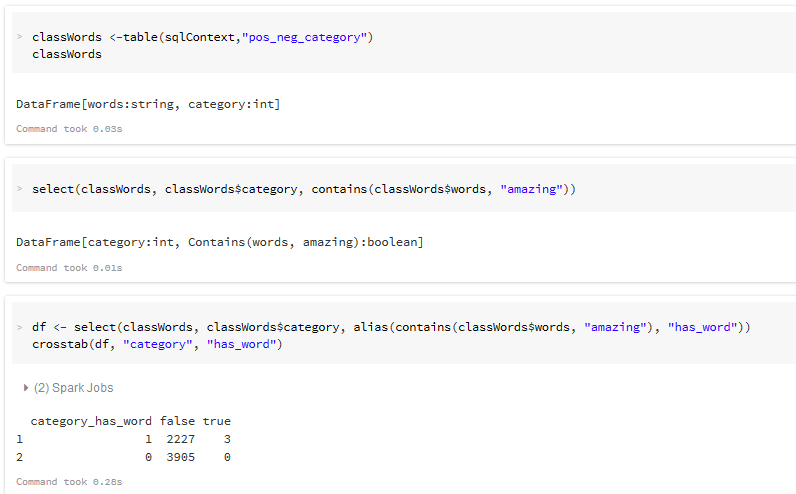
Convert to DataFrame in R
4. Build a Machine Learning Classification Algorithm Pipeline
- Pipeline without loop
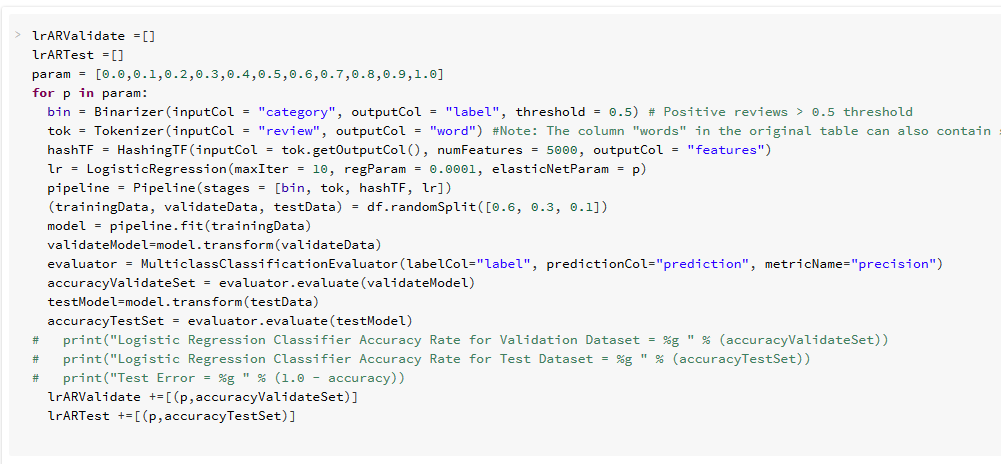
- Pipeline with loop
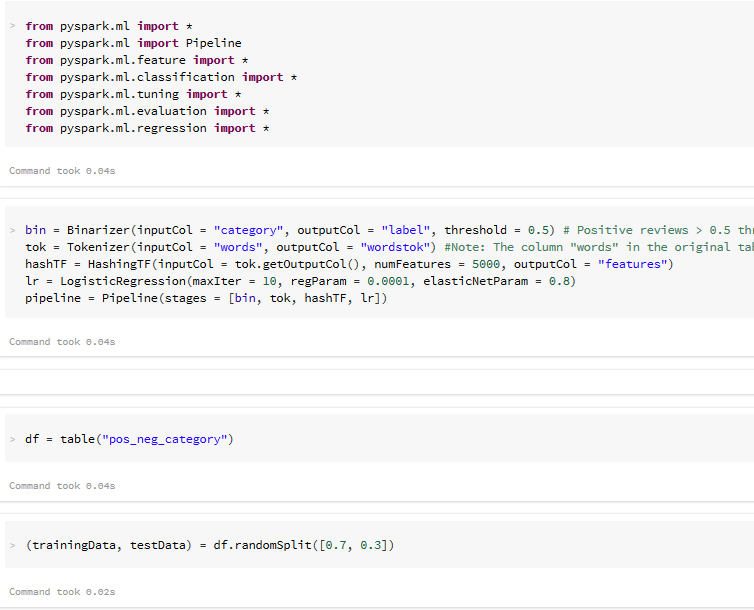
Machine Learning Pipeline: Training and Testing Datasets in Python
- Randomly Split the Hashed Featuresets into Training and Testing Datasets
- Binary Classification Estimator (LogisticRegression)
- Fit the model with training dataset
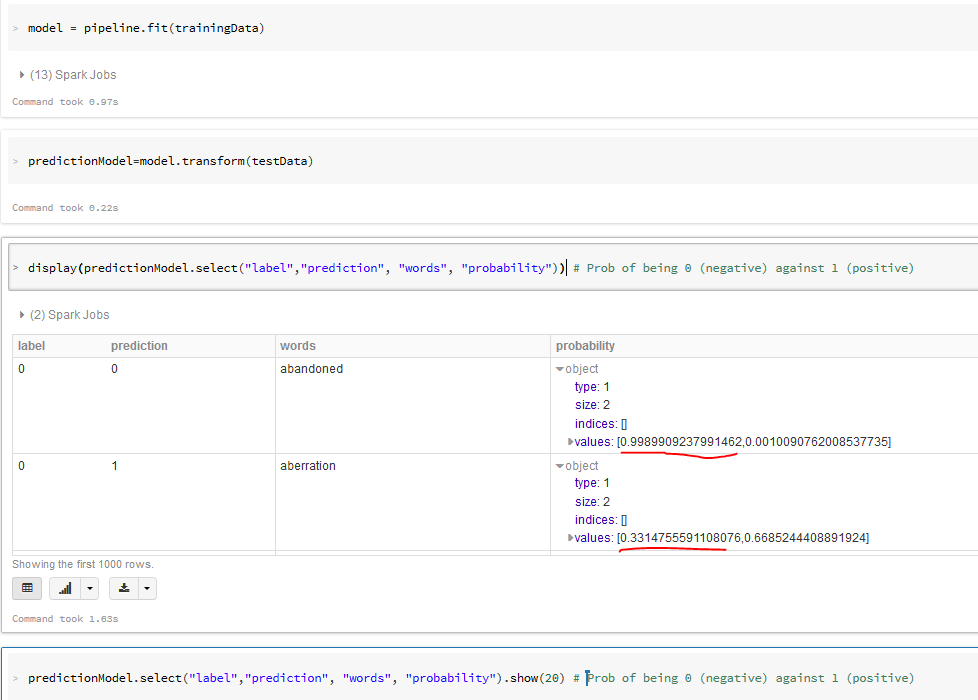
- Transform the trainned model and evaluate using the testing dataset
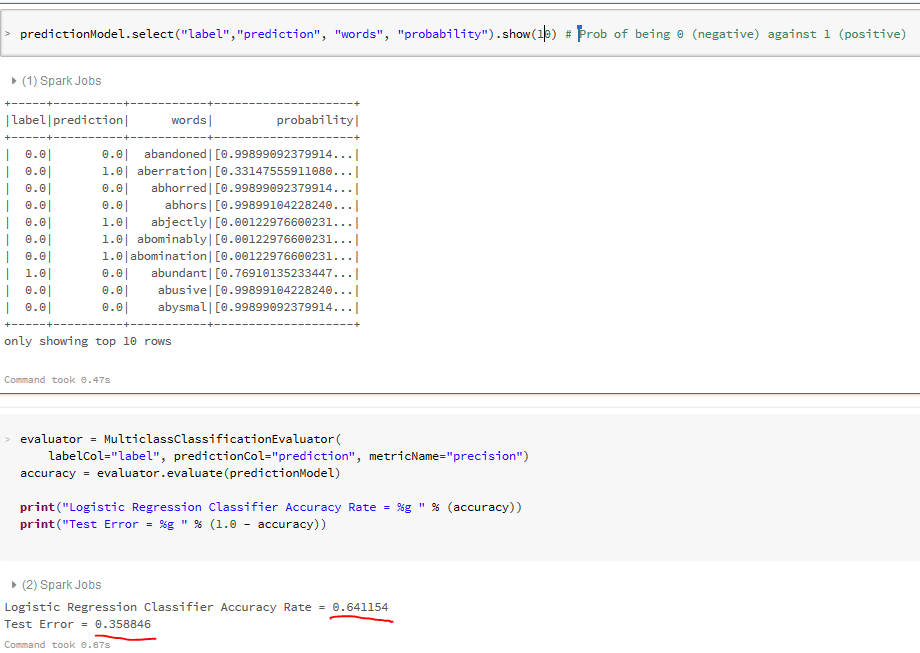
- Compare the label and prediction
- Evaluate the designed ML Logistic Classifier Algorithm (using the Class Evaluator Module in Spark)
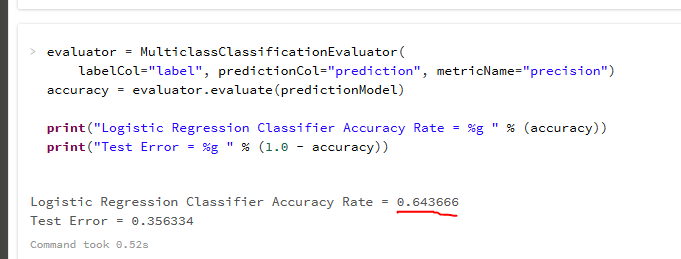
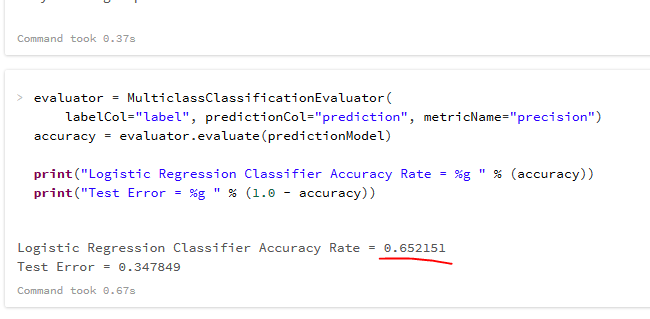
- Accuracy + Test Error = 1
- It can also be implemented in Scala
Machine Learning Pipeline without Loop
Machine Learning Pipeline with Loop
5. Create job to continuously train the algorithm
- Create a job task, upload the pipeline notebook, schedule the job and set notification mail
Production and Scheduled Job for Continous Training of the Algorithm
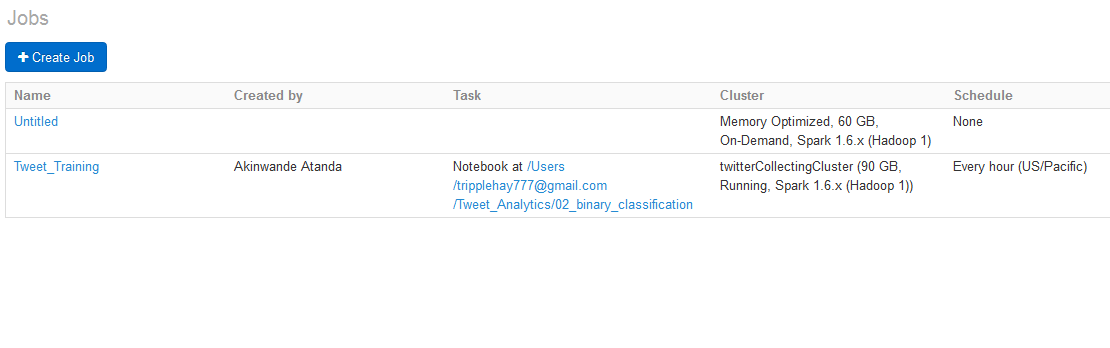
Job notification and updates
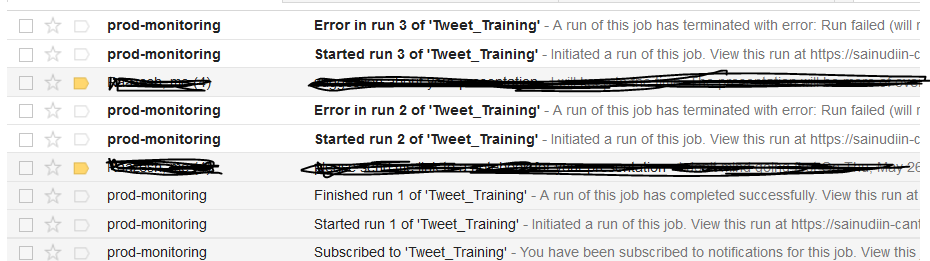
Track the progress of the job
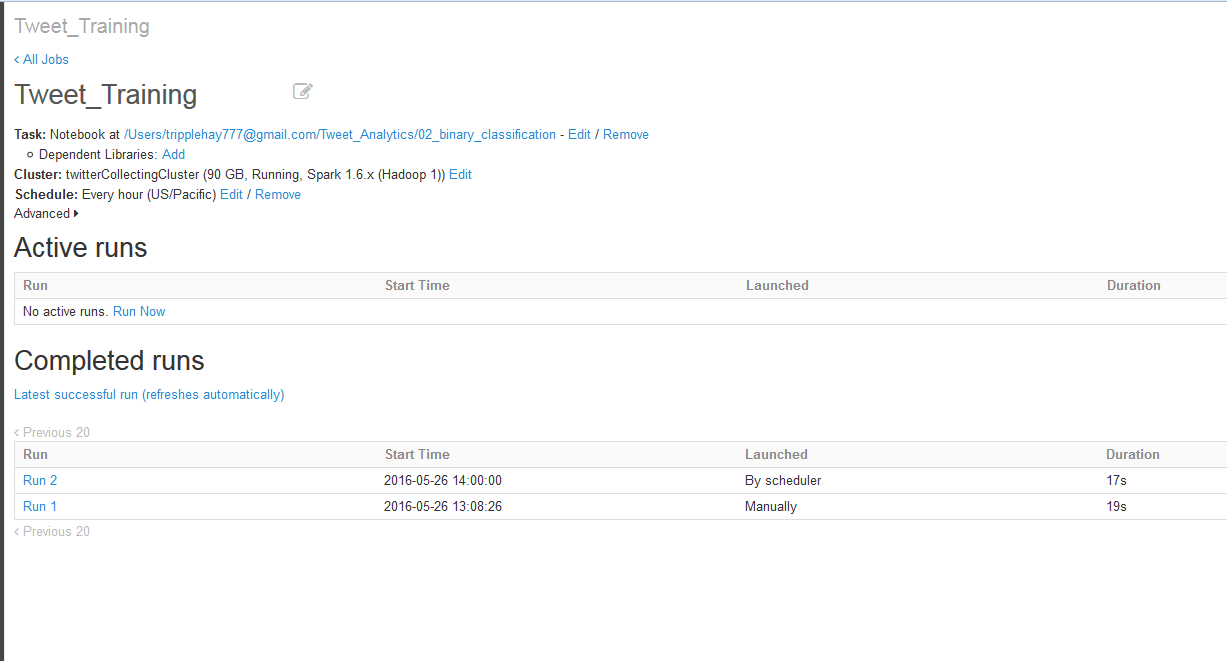
Compare the predicted features of each run
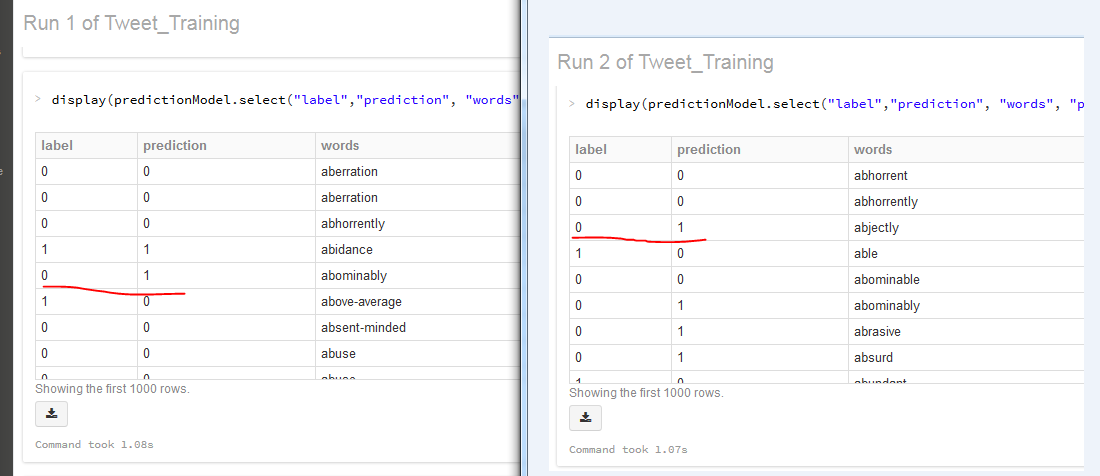
Accuracy Rate from Run 1
Accuracy Rate from Run 2
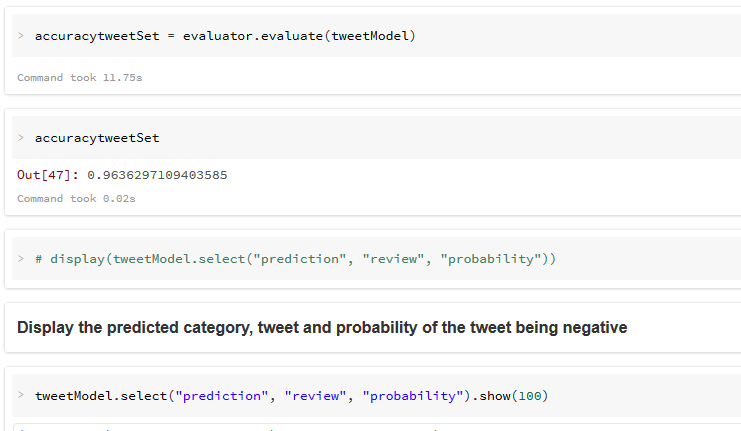
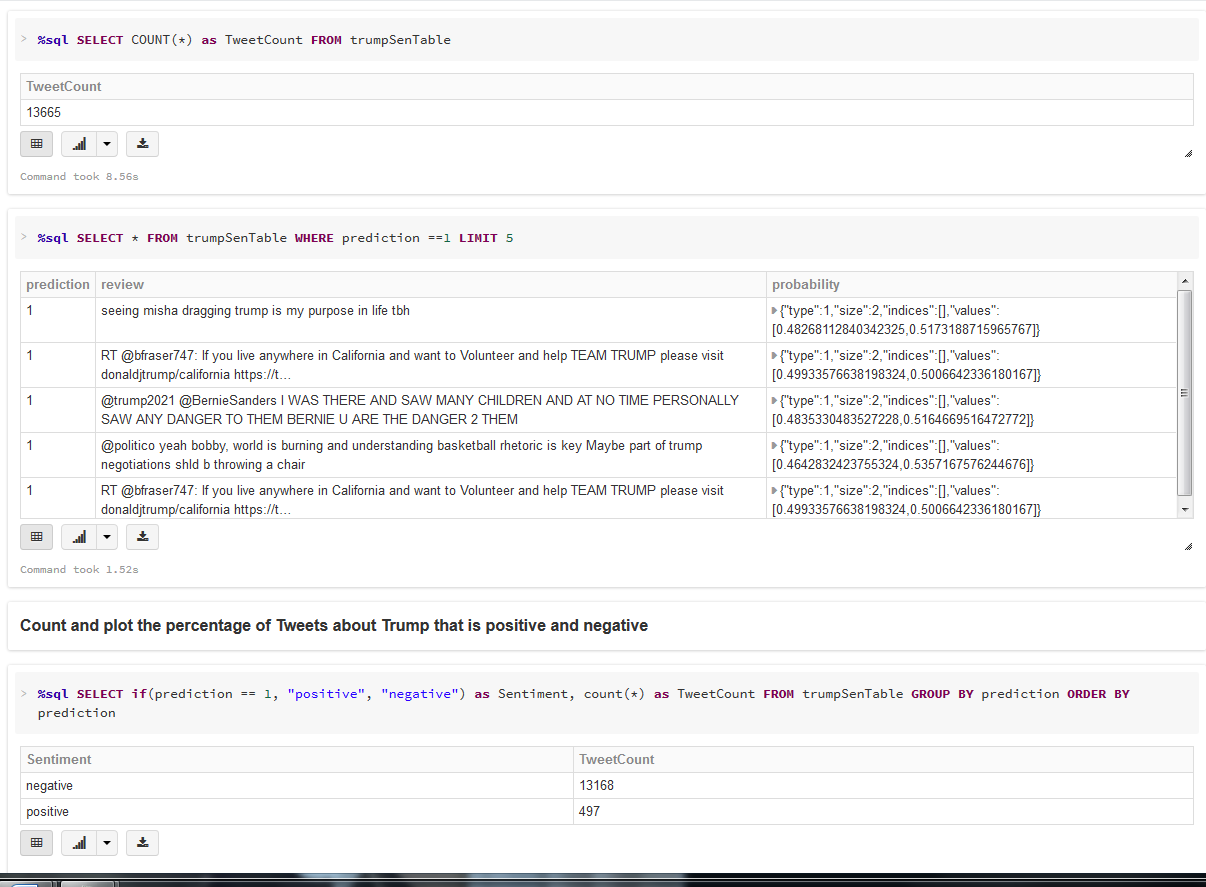
6. Productionize the fitted Algorithm for Sentiment Analysis
Scalable Data Science
Course Project by Akinwande Atanda
supported by
and