// Databricks notebook source exported at Thu, 16 Jun 2016 07:55:27 UTC
Scalable Data Science
prepared by Raazesh Sainudiin and Sivanand Sivaram
supported by  and
and

The html source url of this databricks notebook and its recorded Uji  :
:
The Berkeley Data Analytics Stack is BDAS
Spark is a sub-stack of BDAS
Source:
- Ion Stoica's State of Spark Union AmpCamp 6, Nov 2015
- Machine learning: Trends, perspectives, and prospects, M. I. Jordan, T. M. Mitchell, Science 17 Jul 2015: Vol. 349, Issue 6245, pp. 255-260, DOI: 10.1126/science.aaa8415
BDAS State of The Union Talk by Ion Stoica, AMP Camp 6, Nov 2015
The followign talk outlines the motivation and insights behind BDAS' research approach and how they address the cross-disciplinary nature of Big Data challenges and current work.
- watch now (5 mins.):

key points
- started in 2011 with strong public-private funding
- Defense Advanced Research Projects Agency
- Lawrance Berkeley Laboratory
- National Science Foundation
- Amazon Web Services
- SAP
- The Berkeley AMPLab is creating a new approach to data analytics to seamlessly integrate the three main resources available for making sense of data at scale:
- Algorithms (machine learning and statistical techniques),
- Machines (in the form of scalable clusters and elastic cloud computing), and
- People (both individually as analysts and in crowds).
- The lab is realizing its ideas through the development of a freely-available Open Source software stack called BDAS: the Berkeley Data Analytics Stack.
- Several components of BDAS have gained significant traction in industry and elsewhere, including:
- the Mesos cluster resource manager,
- the Spark in-memory computation framework, a sub-stack of the BDAS stack,
- and more...
The big data problem, Hardware, distributing work, handling failed and slow machines
by Anthony Joseph in BerkeleyX/CS100.1x
- (watch now 1:48): The Big Data Problem
- (watch now 1:43): Hardware for Big Data
- (watch now 1:17): How to distribute work across a cluster of commodity machines?
- (watch now 0:36): How to deal with failures or slow machines?




MapReduce and Apache Spark.
by Anthony Joseph in BerkeleyX/CS100.1x
- (watch now 1:48): Map Reduce (is bounded by Disk I/O)
- (watch now 2:49): Apache Spark (uses Memory instead of Disk)
- (watch now 3:00): Spark Versus MapReduce
- SUMMARY
- uses memory instead of disk alone and is thus fater than Hadoop MapReduce
- resilience abstraction is by RDD (resilient distributed dataset)
- RDDs can be recovered upon failures from their lineage graphs, the recipes to make them starting from raw data
- Spark supports a lot more than MapReduce, including streaming, interactive in-memory querying, etc.
- Spark demonstrated an unprecedented sort of 1 petabyte (1,000 terabytes) worth of data in 234 minutes running on 190 Amazon EC2 instances (in 2015).
- Spark expertise corresponds to the highest Median Salary in the US (~ 150K)



Key Papers
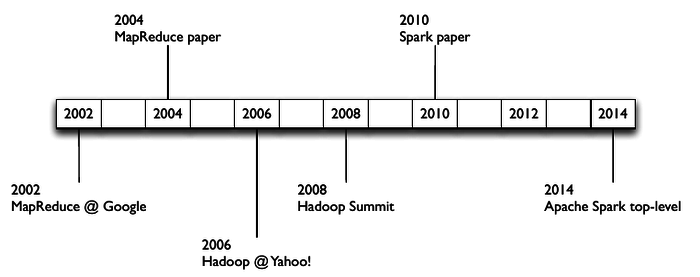
- Key Historical Milestones
- 1956-1979: Stanford, MIT, CMU, and other universities develop set/list operations in LISP, Prolog, and other languages for parallel processing
- 2004: READ: Google's MapReduce: Simplified Data Processing on Large Clusters, by Jeffrey Dean and Sanjay Ghemawat
- 2006: Yahoo!'s Apache Hadoop, originating from the Yahoo!’s Nutch Project, Doug Cutting
- 2009: Cloud computing with Amazon Web Services Elastic MapReduce, a Hadoop version modified for Amazon Elastic Cloud Computing (EC2) and Amazon Simple Storage System (S3), including support for Apache Hive and Pig.
- 2010: READ: The Hadoop Distributed File System, by Konstantin Shvachko, Hairong Kuang, Sanjay Radia, and Robert Chansler. IEEE MSST
Apache Spark Core Papers</h1>
- 2010: Spark: Cluster Computing with Working Sets, Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, Ion Stoica. USENIX HotCloud.
- 2012: READ: Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing, Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker and Ion Stoica. NSDI
55 minutes 55 out of 90+10 minutes.
We have come to the end of this section.
Next let us get everyone to login to databricks to get our hands dirty with some Spark code!
10-15 minutes. Then break for 5.
EXTRA: For a historical insight see excerpts from an interview with Ion Stoica
Beginnings of Apache Spark and Databricks (academia-industry roots)

Advantages of Apache Spark: A Unified System for Batch, Stream, Interactive / Ad Hoc or Graph Processing
Main Goal of Databricks Cloud: To Make Big Data Easy
Scalable Data Science
prepared by Raazesh Sainudiin and Sivanand Sivaram
supported by
and