// Databricks notebook source exported at Thu, 16 Jun 2016 08:21:33 UTC
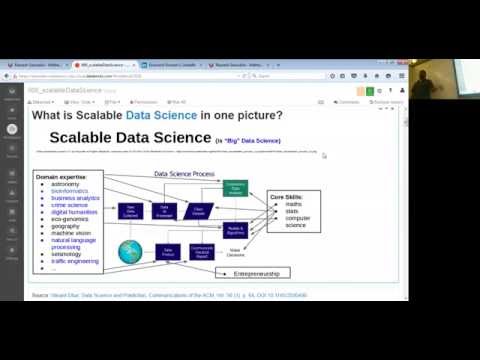
Scalable Data Science
prepared by Raazesh Sainudiin and Sivanand Sivaram
supported by 
and
The html source url of this databricks notebook and its recorded Uji  :
:
Notebooks
Write Spark code for processing your data in notebooks.
NOTE: You should have already cloned this notebook and attached it to the studentsEnrolled or studentsObserving1 clusters by now. If not seek help from Siva by raising your hand.
Notebooks can be written in Python, Scala, R, or SQL.
- This is a Scala notebook - which is indicated next to the title above by
(Scala).
Creating a new Notebook

- Click the tiangle on the right side of a folder to open the folder menu.
- Select Create > Notebook.
- Enter the name of the notebook, the language (Python, Scala, R or SQL) for the notebook, and a cluster to run it on.
Cloning a Notebook
- You can clone a notebook to create a copy of it, for example if you want to edit or run an Example notebook like this one.
- Click File > Clone in the notebook context bar above.
- Enter a new name and location for your notebook. If Access Control is enabled, you can only clone to folders that you have Manage permissions on.
Introduction to Scala through Scala Notebook
- This introduction notebook describes how to get started running Scala code in Notebooks.
Clone Or Import This Notebook
- From the File menu at the top left of this notebook, choose Clone or click Import Notebook on the top right. This will allow you to interactively execute code cells as you proceed through the notebook.

- Enter a name and a desired location for your cloned notebook (i.e. Perhaps clone to your own user directory or the "Shared" directory.)
- Navigate to the location you selected (e.g. click Menu > Workspace >
Your cloned location)
Attach the Notebook to a cluster
- A Cluster is a group of machines which can run commands in cells.
- Check the upper left corner of your notebook to see if it is Attached or Detached.
- If Detached, click on the right arrow and select a cluster to attach your notebook to.
- If there is no running cluster, create one as described in the Welcome to Databricks guide.

 Cells are units that make up notebooks
Cells are units that make up notebooks

Cells each have a type - including scala, python, sql, R, markdown, filesystem, and shell.
- While cells default to the type of the Notebook, other cell types are supported as well.
- This cell is in markdown and is used for documentation. Markdown is a simple text formatting syntax.
Create and Edit a New Markdown Cell in this Notebook
When you mouse between cells, a + sign will pop up in the center that you can click on to create a new cell.

Type
%md Hello, world!into your new cell (%mdindicates the cell is markdown).Click out of the cell to see the cell contents update.

Running a cell in your notebook.
Press Shift+Enter when in the cell to run it and proceed to the next cell.
- The cells contents should update.
- The cells contents should update.
- NOTE: Cells are not automatically run each time you open it.
- Instead, Previous results from running a cell are saved and displayed.
Alternately, press Ctrl+Enter when in a cell to run it, but not proceed to the next cell.
You Try Now!
Just double-click the cell below, modify the text following %md and press Ctrl+Enter to evaluate it and see it's mark-down'd output.
> %md Hello, world!
Hello, world!
Markdown Cell Tips
- To change a non-markdown cell to markdown, add %md to very start of the cell.
- After updating the contents of a markdown cell, click out of the cell to update the formatted contents of a markdown cell.
- To edit an existing markdown cell, doubleclick the cell.
Run a Scala Cell
- Run the following scala cell.
- Note: There is no need for any special indicator (such as
%md) necessary to create a Scala cell in a Scala notebook. - You know it is a scala notebook because of the
(Scala)appended to the name of this notebook. - Make sure the cell contents updates before moving on.
- Press Shift+Enter when in the cell to run it and proceed to the next cell.
- The cells contents should update.
- Alternately, press Ctrl+Enter when in a cell to run it, but not proceed to the next cell.
- characters following
//are comments in scala.
println(System.currentTimeMillis) // press Ctrl+Enter to evaluate println that prints its argument as a line
Scala Resources
You will not be learning scala systematically and thoroughly in this course. You will learn to use Scala by doing various Spark jobs.
If you are seriously interested in learning scala properly, then there are various resources, including:
- scala-lang.org is the core Scala resource.
- MOOC
- Books
The main sources for the following content are (you are encouraged to read them for more background):
- Martin Oderski's Scala by example
- Scala crash course by Holden Karau
- Darren's brief introduction to scala and breeze for statistical computing
Introduction to Scala
What is Scala?
"Scala smoothly integrates object-oriented and functional programming. It is designed to express common programming patterns in a concise, elegant, and type-safe way." by Matrin Odersky.
- High-level language for the Java Virtual Machine (JVM)
- Object oriented + functional programming
- Statically typed
- Comparable in speed to Java
- Type inference saves us from having to write explicit types most of the time Interoperates with Java
- Can use any Java class (inherit from, etc.)
- Can be called from Java code
Why Scala?
- Spark was originally written in Scala, which allows concise function syntax and interactive use
- Spark APIs for other languages include:
- Java API for standalone use
- Python API added to reach a wider user community of programmes
- R API added more recently to reach a wider community of data analyststs
- Unfortunately, Python and R APIs are generally behind Spark's native Scala (for eg. GraphX is only available in Scala currently).
- See Darren Wilkinson's 11 reasons for scala as a platform for statistical computing and data science. It is embedded in-place below for your convenience.
%run "/scalable-data-science/xtraResources/support/sdsFunctions"
displayHTML(frameIt("https://darrenjw.wordpress.com/2013/12/23/scala-as-a-platform-for-statistical-computing-and-data-science/",500))
Let's get our hands dirty in Scala
We will go through the following programming concepts and tasks:
- Assignments
- Methods and Tab-completion
- Functions in Scala
- Collections in Scala
- Scala Closures for Functional Programming and MapReduce
Remark: You need to take a computer science course (from CourseEra, for example) to properly learn Scala. Here, we will learn to use Scala by example to accomplish our data science tasks at hand.
Assignments
value and variable as val and var
Let us assign the integer value 5 to x as follows:
val x : Int = 5 // <Ctrl+Enter> to declare a value x to be integer 5
Scala is statically typed, but it uses built-in type inference machinery to automatically figure out that x is an integer or Int type as follows.
Let's declare a value x to be Int 5 next without explictly using Int.
val x = 5 // <Ctrl+Enter> to declare a value x as Int 5 (type automatically inferred)
Let's declare x as a Double or double-precision floating-point type using decimal such as 5.0 (a digit has to follow the decimal point!)
val x = 5.0 // <Ctrl+Enter> to declare a value x as Double 5
Alternatively, we can assign x as a Double explicitly. Note that the decimal point is not needed in this case due to explicit typing as Double.
val x : Double = 5 // <Ctrl+Enter> to declare a value x as Double 5 (type automatically inferred)
Next note that labels need to be declared on first use. We have declared x to be a val which is short for value. This makes x immutable (cannot be changed).
Thus, x cannot be just re-assigned, as the following code illustrates in the resulting error: ... error: reassignment to val.
x = 10 // <Ctrl+Enter> to try to reassign val x to 10
Scala allows declaration of mutable variables as well using var, as follows:
var y = 2 // <Shift+Enter> to declare a variable y to be integer 2 and go to next cell
y = 3 // <Shift+Enter> to change the value of y to 3
Methods and Tab-completion
val s = "hi" // <Ctrl+Enter> to declare val s to String "hi"
You can place the cursor after . following a declared object and find out the methods available for it as shown in the image below.

You Try doing this next.
s. // place cursor after the '.' and press Tab to see all available methods for s
For example,
- scroll down to
containsand double-click on it. - This should lead to
s.containsin your cell. - Now add an argument String to see if
scontains the argument, for example, try:s.contains("f")s.contains("")ands.contains("i")
s // <Shift-Enter> recall the value of String s
s.contains("f") // <Shift-Enter> returns Boolean false since s does not contain the string "f"
s.contains("") // <Shift-Enter> returns Boolean true since s contains the empty string ""
s.contains("i") // <Ctrl+Enter> returns Boolean true since s contains the string "i"
Functions
def square(x: Int): Int = x*x // <Shitf+Enter> to define a function named square
square(5) // <Shitf+Enter> to call this function on argument 5
y // <Shitf+Enter> to recall that val y is Int 3
square(y) // <Shitf+Enter> to call the function on val y of the right argument type Int
x // <Shitf+Enter> to recall x is Double 5.0
square(x) // <Shift+Enter> to call the function on val x of type Double will give type mismatch error
def square(x: Int): Int = { // <Shitf+Enter> to declare function in a block
val answer=x*x
answer // the last line of the function block is returned
}
square(5000) // <Shift+Enter> to call the function
// <Shift+Enter> to define function with input and output type as String
def announceAndEmit(text: String) =
{
println(text)
text // the last line of the function block is returned
}
// <Ctrl+Enter> to call function which prints as line and returns as String
announceAndEmit("roger roger")
Scala Collections
See the overview and introduction to scala collections, the building blocks of Spark.
// <Ctrl+Enter> to declare (an immutable) val lst as List of Int's 1,2,3
val lst = List(1, 2, 3)
There are several other Scala collections and we will introduce them as needed. The two other most common ones are Array and Seq.
val arr = Array(1,2,3) // <Shift-Enter> to declare an Array
val seq = Seq(1,2,3) // <Shift-Enter> to declare a Seq
Scala Closures for Functional Programming and MapReduce
We will apply such closures for processing scala collections with functional programming.
Five ways of adding 1
explicit version:
(x: Int) => x + 1type-inferred more intuitive version:
x => x + 1placeholder syntax (each argument must be used exactly once):
_ + 1type-inferred more intuitive version with code-block for larger function body:
x => { // body is a block of code val integerToAdd = 1 x + integerToAdd }regular functions using
def:def addOne(x: Int): Int = x + 1
Now, let's apply closures for functional programming over scala collection (List) using foreach, map, filter and reduce. In the end we will write out first mapReduce program!
// <Shift+Enter> to call the foreach method and print its contents element-per-line using println function
lst.foreach(x => println(x))
// <Shift+Enter> for same output as above where println is applied to each element of List lst
lst.foreach(println)
// <Shift+Enter> to map each value x of lst with x+10 to return a new List(11, 12, 13)
lst.map(x => x + 10)
// <Shift+Enter> for the same as above using place-holder syntax
lst.map(_ + 10)
// <Shift+Enter> to return a new List(1, 3) after filtering x's from lst if (x % 2 == 1) is true
lst.filter(x => (x % 2 == 1) )
// <Shift+Enter> for the same as above using place-holder syntax
lst.filter( _ % 2 == 1 )
// <Shift+Enter> to use reduce to add elements of lst two at a time to return Int 6
lst.reduce( (x, y) => x + y )
// <Ctrl+Enter> for the same as above but using place-holder syntax
lst.reduce( _ + _ )
Let's combine map and reduce programs above to find the sum of after 10 has been added to every element of the original List lst as follows:
lst.map(x => x+10).reduce((x,y) => x+y) // <Ctrl-Enter> to get Int 36 = sum(1+10,2+10,3+10)
There are lots of methods in Scala Collections. See for example API_scala.collection.Seq.
Spark is written in Scala and the primary language for this course is Scala.
However, let us use the best language for the job!
Cells each have a type - scala, python, r, sql, filesystem, command line or markdown.
- While cells default to the type of the Notebook, other cell types are supported as well.
- For example, Python Notebooks can contain python, sql, markdown, and even Scala cells. This lets you write notebooks that do use multiple languages.
- This cell is in markdown and is used for documentation purposes.
All types of cells can be created in any notebook, regardless of the language.
To create a cell of another language, start the cell with:
%md- Markdown%sql- SQL%scala- Scala%py- Python%r- R
Cross-language cells can be used to mix commands from other languages.
Examples:
%py print("For example, this is a scala notebook, but we can use %py to run python commands inline.")
%r print("We can also access other languages such as R.")
Command line cells can be used to work with local files on the Spark driver node.
- Start a cell with
%shto run a command line command
%sh
# This is a command line cell. Commands you write here will be executed as if they were run on the command line.
# For example, in this cell we access the help pages for the bash shell.
man bash
Filesystem cells allow access to the Databricks File System.
- Start a cell with
%fsto run DBFS commands - Type
%fs helpfor a list of commands
Further Reference / Homework
Go through the following notebooks (File and Clone them into your Workspace/Users/...) to play and familiarize yourself with databricks cloud:
- Welcome to Databricks and watch the Getting Started videos for more details. This worksheet can be loaded below using
%run "/databricks_guide/00 Welcome to Databricks" - Intro Scala Notebooks
- Databricks File System
- FileStore to organize files for access.
You may also like to check out:
Notebooks can be run from other notebooks using %run
- Syntax:
%run /full/path/to/notebook - This is commonly used to import functions you defined in other notebooks.
%run "/databricks_guide/00 Welcome to Databricks" // running this cell will load databricks_guide/00 Welcome to Databricks notebook here
Scalable Data Science
prepared by Raazesh Sainudiin and Sivanand Sivaram
supported by
and