// Databricks notebook source exported at Thu, 16 Jun 2016 07:32:05 UTC
Scalable Data Science
prepared by Raazesh Sainudiin and Sivanand Sivaram
supported by 
and
The html source url of this databricks notebook and its recorded Uji  :
:
A bit about who your instructors are:
- Raaz from academia (10 years + 1 year in industry) https://nz.linkedin.com/in/raazesh-sainudiin-45955845 and Raaz's academic CV and
- Siva from industry (11 years) https://www.linkedin.com/in/sivanand
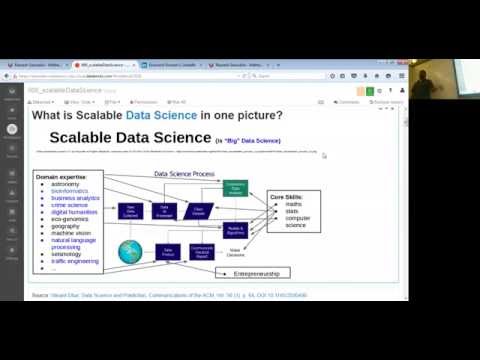
What is Scalable Data Science in one picture?

key insights
- Data Science is the study of the generalizabile extraction of knowledge from data.
- A common epistemic requirement in assessing whether new knowledge is actionable for decision making is its predictive power, not just its ability to explain the past.
- A data scientist requires an integrated skill set spanning
- mathematics,
- machine learning,
- artificial intelligence,
- statistics,
- databases, and
- optimization,
- along with a deep understanding of the craft of problem formulation to engineer effective solutions.
key insights
- ML is concerned with the building of computers that improve automatically through experience
- ML lies at the intersection of computer science and statistics and at the core of artificial intelligence and data science
- Recent progress in ML is due to:
- development of new algorithms and theory
- ongoing explosion in the availability of online data
- availability of low-cost computation (_through clusters of commodity hardware in the _cloud* )
- The adoption of data science and ML methods is leading to more evidence-based decision-making across:
- health sciences (neuroscience research, )
- manufacturing
- robotics (autonomous vehicle)
- vision, speech processing, natural language processing
- education
- financial modeling
- policing
- marketing
Standing on shoulders of giants!
This course will build on two other edX courses where needed.
- BerkeleyX/CS100-1x, Introduction to Big Data Using Apache Spark by Anthony A Joseph, Chancellor's Professor, UC Berkeley
- BerkeleyX/CS190-1x, Scalable Machine Learning by Ameet Talwalkar, Ass. Prof., UC Los Angeles
We encourage you to take these courses if you have more time. For those of you (including the course coordinator) who have taken these courses formally in 2015, this course will be an expanded scala version with an emphasis on individualized course project as opposed to completing labs that test sytactic skills.
We will also be borrowing more theoretical aspects from the following course:
The two recommended readings are (already somewhat outdated!):
- Learning Spark : lightning-fast data analytics by Holden Karau, Andy Konwinski, Patrick Wendell, and Matei Zaharia, O'Reilly, 2015.
- Advanced analytics with Spark : patterns for learning from data at scale, O'Reilly, 2015.
 and
and
These are available at UC Library
How will you be assessed?
The course is extremely hands-on and therefore gives 50% of the final grade for attending each lab and completing it. Completing a lab essentially involves going through the cells in the cloned notebooks for each week to strengthen your understanding. This will ensure that the concept as well as the syntax is understood for the learning outcomes for each week. There are additional videos and exercises you are encouraged to watch/complete. These additional exercises will not be graded. You may use 1800-1830 hours to ask any questions about the contents in the current or previous weeks.
Each student will be working on a course project and present the findings to the class in the last week or two. The course project will be done in http://www.math.canterbury.ac.nz/databricks-projects and counts towards 50% of the final grade. The project will typically involve applying Spark on a publicly available dataset or writing a report to demonstrate in-depth understanding of appropriate literature of interest to the student’s immediate research goals in academia or industry. Oral presentation of the project will constitute 10% of the grade. The remaining 40% of the grade will be for the written part of the project, which will be graded for replicability and ease of understanding. The written report will be encouraged for publication in a technical blog format in public repositories such as GitHub through a publishable mark-down'd databricks notebook (this is intended to show-case the actual skills of the student to potential employers directly). Group work on projects may be considered for complex projects.
A Brief History of Data Analysis and Where Does "Big Data" Come From?
by Anthony Joseph in BerkeleyX/CS100.1x
(watch now 1:53): A Brief History of Data Analysis
(watch now 5:05): Where does Data Come From?

- SUMMARY of Some of the sources of big data.
- online click-streams (a lot of it is recorded but a tiny amount is analyzed):
- record every click
- every ad you view
- every billing event,
- every transaction, every network message, and every fault.
- User-generated content (on web and mobile devices):
- every post that you make on Facebook
- every picture sent on Instagram
- every review you write for Yelp or TripAdvisor
- every tweet you send on Twitter
- every video that you post to YouTube.
- Science (for scientific computing):
- data from various repositories for natural language processing:
- Wikipedia,
- the Library of Congress,
- twitter firehose and google ngrams and digital archives,
- data from scientific instruments/sensors/computers:
- the Large Hadron Collider (more data in a year than all the other data sources combined!)
- genome sequencing data (sequencing cost is dropping much faster than Moore's Law!)
- output of high-performance computers (super-computers) for data fusion, estimation/prediction and exploratory data analysis
- Graphs are also an interesting source of big data (network science).
- social networks (collaborations, followers, fb-friends or other relationships),
- telecommunication networks,
- computer networks,
- road networks
- machine logs:
- by servers around the internet (hundreds of millions of machines out there!)
- internet of things.
- data from various repositories for natural language processing:
- online click-streams (a lot of it is recorded but a tiny amount is analyzed):

Data Science Defined, Cloud Computing and What's Hard About Data Science?
by Anthony Joseph in BerkeleyX/CS100.1x
- (watch now 2:03): Data Science Defined
- (watch now 1:11): Cloud Computing

- In fact, if you are logged into
https://*.databricks.com/*you are computing in the cloud! - The Scalable Data Science course is supported by Databricks Academic Partners Program and the AWS Educate Grant to University of Canterbury (applied by Raaz Sainudiin in 2015).
- (watch now 3:31): What's hard about data science


What should you be able to do at the end of this course?
- by following these sessions and doing some HOMEWORK expected of an honours UC student.
Understand the principles of fault-tolerant scalable computing in Spark
- in-memory and generic DAG extensions of Map-reduce
- resilient distributed datasets for fault-tolerance
- skills to process today's big data using state-of-the art techniques in Apache Spark 1.6, in terms of:
- hands-on coding with real datasets
- an intuitive (non-mathematical) understanding of the ideas behind the technology and methods
- pointers to academic papers in the literature, technical blogs and video streams for you to futher your theoretical understanding.
More concretely, you will be able to:
1. Extract, Transform, Load, Interact, Explore and Analyze Data
(watch later) Exploring Apache Web Logs (semi-structured data) - topic of weeks 2/3
(watch later) Exploring Wikipedia Click Streams (structured data) - topic of weeks 2/3
2. Build Scalable Machine Learning Pipelines
Apply standard learning methods via scalably servable end-to-end industrial ML pipelines
ETL, Model, Validate, Test, reETL (feature re-engineer), model validate, test,..., serve model to clients
(we will choose from this list)
- Supervised Learning Methods: Regression /Classification
- Unsupervised Learning Methods: Clustering
- Recommedation systems
- Streaming
- Graph processing
- Geospatial data-processing
- Topic modeling
- Deep Learning
- ...
(watch later) Spark Summit 2015 demo: Creating an end-to-end machine learning data pipeline with Databricks (Live Sentiment Analysis)

20 minutes of 90+10 minutes are up!
EXTRA: Databases Versus Data Science
by Anthony Joseph in BerkeleyX/CS100.1x
- (watch later 2:31): Why all the excitement about Big Data Analytics? (using google search to now-cast google flu-trends)
other interesting big data examples - recommender systems and netflix prize?
(watch later 10:41): Contrasting data science with traditional databases, ML, Scientific computing

- SUMMARY:
- traditional databases versus data science
- preciousness versus cheapness of the data
- ACID and eventual consistency, CAP theorem, ...
- interactive querying: SQL versus noSQL
- querying the past versus querying/predicting the future
- traditional scientific computing versus data science
- science-based or mechanistic models versus data-driven black-box (deep-learning) statistical models (of course both schools co-exist)
- super-computers in traditional science-based models versus cluster of commodity computers
- traditional ML versus data science
- smaller amounts of clean data in traditional ML versus massive amounts of dirty data in data science
- traditional ML researchers try to publish academic papers versus data scientists try to produce actionable intelligent systems
- traditional databases versus data science
(watch later 1:49): Three Approaches to Data Science
- (watch later 4:29): Performing Data Science and Preparing Data, Data Acquisition and Preparation, ETL, ...
- (watch later 2:01): Four Examples of Data Science Roles

- SUMMARY of Data Science Roles.
- individual roles:
- business person
- programmer
- organizational roles:
- enterprise
- web company
- individual roles:
- Each role has it own unique set of:
- data sources
- Extract-Transform-Load (ETL) process
- business intelligence and analytics tools
- Most Maths/Stats/Computing programs cater to the programmer role
- Numpy and Matplotlib, R, Matlab, and Octave.



Scalable Data Science
prepared by Raazesh Sainudiin and Sivanand Sivaram
supported by
and