// Databricks notebook source exported at Fri, 24 Jun 2016 23:58:12 UTC
Scalable Data Science
prepared by Raazesh Sainudiin and Sivanand Sivaram
supported by  and
and

The html source url of this databricks notebook and its recorded Uji  :
:
Tweet Collector - capture live tweets
First let's take the twitter stream and write to DBFS as json files
See the notebook 022_TweetGenericCollector (this notebook is not robust and it is only for demo)!!!
import org.apache.spark._
import org.apache.spark.storage._
import org.apache.spark.streaming._
import org.apache.spark.streaming.twitter.TwitterUtils
import twitter4j.auth.OAuthAuthorization
import twitter4j.conf.ConfigurationBuilder
Let's create a directory in dbfs for storing tweets in the cluster's distributed file system.
val rawTweetsDirectory="/rawTweets"
dbutils.fs.rm(rawTweetsDirectory, true) // to remove a pre-existing directory and start from scratch uncomment and evaluate this cell
Capture tweets in every sliding window of slideInterval many milliseconds.
val slideInterval = new Duration(1 * 1000) // 1 * 1000 = 1000 milli-seconds = 1 sec
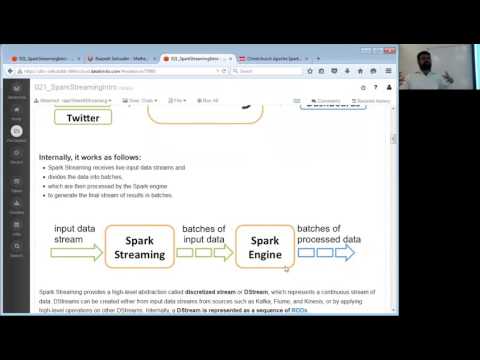
Recall that Discretized Stream or DStream is the basic abstraction provided by Spark Streaming. It represents a continuous stream of data, either the input data stream received from source, or the processed data stream generated by transforming the input stream. Internally, a DStream is represented by a continuous series of RDDs, which is Spark?s abstraction of an immutable, distributed dataset (see Spark Programming Guide for more details). Each RDD in a DStream contains data from a certain interval, as shown in the following figure.

Let's import googles json library next.
import com.google.gson.Gson // the Library has already been attached to this cluster (show live how to do this from scratch?)
Our goal is to take each RDD in the twitter DStream and write it as a json file in our dbfs.
// Create a Spark Streaming Context.
val ssc = new StreamingContext(sc, slideInterval)
CAUTION: Extracting knowledge from tweets is "easy" using techniques shown here, but one has to take responsibility for the use of this knowledge and conform to the rules and policies linked below.
Remeber that the use of twitter itself comes with various strings attached. Read:
Crucially, the use of the content from twitter by you (as done in this worksheet) comes with some strings. Read:
Enter your own Twitter API Credentials.
- Go to https://apps.twitter.com and look up your Twitter API Credentials, or create an app to create them.
- Run this cell for the input cells to appear.
- Enter your credentials.
- Run the cell again to pick up your defaults.
The cell-below is hidden to not expose the Twitter API Credentials: consumerKey, consumerSecret, accessToken and accessTokenSecret.
System.setProperty("twitter4j.oauth.consumerKey", getArgument("1. Consumer Key (API Key)", ""))
System.setProperty("twitter4j.oauth.consumerSecret", getArgument("2. Consumer Secret (API Secret)", ""))
System.setProperty("twitter4j.oauth.accessToken", getArgument("3. Access Token", ""))
System.setProperty("twitter4j.oauth.accessTokenSecret", getArgument("4. Access Token Secret", ""))
If you see warnings then ignore for now: https://forums.databricks.com/questions/6941/change-in-getargument-for-notebook-input.html.
// Create a Twitter Stream for the input source.
val auth = Some(new OAuthAuthorization(new ConfigurationBuilder().build()))
val twitterStream = TwitterUtils.createStream(ssc, auth)
Let's map the tweets into json formatted string (one tweet per line).
val twitterStreamJson = twitterStream.map(x => { val gson = new Gson();
val xJson = gson.toJson(x)
xJson
})
var numTweetsCollected = 0L // track number of tweets collected
val partitionsEachInterval = 1 // This tells the number of partitions in each RDD of tweets in the DStream.
twitterStreamJson.foreachRDD((rdd, time) => { // for each RDD in the DStream
val count = rdd.count()
if (count > 0) {
val outputRDD = rdd.repartition(partitionsEachInterval) // repartition as desired
outputRDD.saveAsTextFile(rawTweetsDirectory + "/tweets_" + time.milliseconds.toString) // save as textfile
numTweetsCollected += count // update with the latest count
}
})
Nothing has actually happened yet.
Let's start the spark streaming context we have created next.
ssc.start()
Let's look at the spark UI now and monitor the streaming job in action! Go to Clusters on the left and click on UI and then Streaming.
numTweetsCollected // number of tweets collected so far
Note that you could easilt fill up disk space!!!
So let's stop the streaming job next.
ssc.stop(stopSparkContext = false) // gotto stop soon!!!
Let's make sure that the Streaming UI is not active in the Clusters UI.
StreamingContext.getActive.foreach { _.stop(stopSparkContext = false) } // extra cautious stopping of all active streaming contexts
Let's examine what was saved in dbfs
display(dbutils.fs.ls("/rawTweets/"))
val tweetsDir = "/rawTweets/tweets_1459392400000/" // use an existing file, may have to rename folder based on output above!
display(dbutils.fs.ls(tweetsDir))
sc.textFile(tweetsDir+"part-00000").count()
val outJson = sqlContext.read.json(tweetsDir+"part-00000")
outJson.printSchema()
outJson.select("id","text").show(false)
Clearly there is a lot one can do with tweets!
Next, let's write the tweets into a scalable commercial cloud storage system
We will make sure to write the tweets to AWS's simple storage service or S3, a scalable storage system in the cloud. See https://aws.amazon.com/s3/.
// Replace with your AWS S3 credentials
//
// NOTE: Set the access to this notebook appropriately to protect the security of your keys.
// Or you can delete this cell after you run the mount command below once successfully.
val AccessKey = getArgument("1. ACCESS_KEY", "REPLACE_WITH_YOUR_ACCESS_KEY")
val SecretKey = getArgument("2. SECRET_KEY", "REPLACE_WITH_YOUR_SECRET_KEY")
val EncodedSecretKey = SecretKey.replace("/", "%2F")
val AwsBucketName = getArgument("3. S3_BUCKET", "REPLACE_WITH_YOUR_S3_BUCKET")
val MountName = getArgument("4. MNT_NAME", "REPLACE_WITH_YOUR_MOUNT_NAME")
val s3Filename = "tweetDump"
Now just mount s3 as follows:
dbutils.fs.mount(s"s3a://$AccessKey:$EncodedSecretKey@$AwsBucketName", s"/mnt/$MountName")
Now you can use the dbutils commands freely to access data in S3.
dbutils.fs.help()
display(dbutils.fs.ls(s"/mnt/")) // list the files in s3
dbutils.fs.cp("dbfs:/rawTweets",s"/mnt/$MountName/rawTweetsInS3/",recurse=true) // copy all the tweets
display(dbutils.fs.ls(s"/mnt/$MountName/rawTweetsInS3")) // list the files copied into s3
dbutils.fs.rm(s"/mnt/$MountName/rawTweetsInS3",recurse=true) // remove all the files from s3
display(dbutils.fs.ls("/mnt/")) // list the files in s3
//display(dbutils.fs.ls(s"/mnt/$MountName/rawTweetsInS3")) // it has been removed
dbutils.fs.unmount(s"/mnt/$MountName") // finally unmount when done
Scalable Data Science
prepared by Raazesh Sainudiin and Sivanand Sivaram
supported by
and