// Databricks notebook source exported at Fri, 24 Jun 2016 23:55:05 UTC
Scalable Data Science
prepared by Raazesh Sainudiin and Sivanand Sivaram
supported by  and
and

The html source url of this databricks notebook and its recorded Uji  :
:
Spark Streaming
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams.
This is an augmentation of the following resources:
- the Databricks Guide Workspace -> Databricks_Guide -> 08 Spark Streaming -> 00 Spark Streaming and
- http://spark.apache.org/docs/latest/streaming-programming-guide.html
Overview
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams.
Data can be ingested from many sources like
- Kafka,
- Flume,
- Twitter Streaming and REST APIs,
- ZeroMQ,
- Amazon Kinesis, or
- TCP sockets,
and can be processed using
complex algorithms expressed with high-level functions like map,
reduce, join and window.
Finally, processed data can be pushed out to filesystems, databases, and live dashboards. In fact, you can apply Spark's
- machine learning and
- graph processing algorithms on data streams.

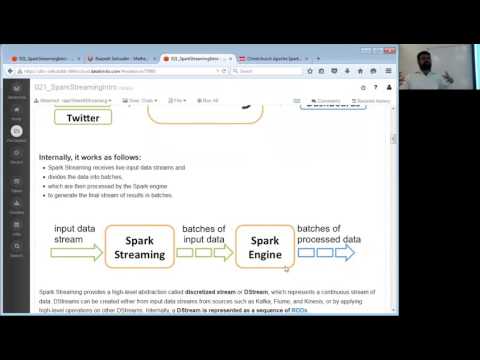
Internally, it works as follows:
- Spark Streaming receives live input data streams and
- divides the data into batches,
- which are then processed by the Spark engine
- to generate the final stream of results in batches.

Spark Streaming provides a high-level abstraction called discretized stream or DStream, which represents a continuous stream of data. DStreams can be created either from input data streams from sources such as Kafka, Flume, and Kinesis, or by applying high-level operations on other DStreams. Internally, a DStream is represented as a sequence of RDDs.
This guide shows you how to start writing Spark Streaming programs with DStreams. You can write Spark Streaming programs in Scala, Java or Python (introduced in Spark 1.2), all of which are presented in this guide.
Here, we will focus on Streaming in Scala.
Spark Streaming Resources
- Spark Streaming Programming Guide - The official Apache Spark Streaming programming guide.
- Debugging Spark Streaming in Databricks
- Streaming FAQs and Best Practices
Three Quick Examples
Before we go into the details of how to write your own Spark Streaming program, let?s take a quick look at what a simple Spark Streaming program looks like.
We will choose the first two examples in Databricks notebooks below.
Spark Streaming Hello World Examples in Databricks Notebooks
- Streaming Word Count (Scala)
- Tweet Collector for Capturing Live Tweets
- Twitter Hashtag Count (Scala)
Other examples we won't try here:
1. Streaming Word Count
This is a hello world example of Spark Streaming which counts words on 1 second batches of streaming data.
It uses an in-memory string generator as a dummy source for streaming data.
Configurations
Configurations that control the streaming app in the notebook
// === Configuration to control the flow of the application ===
val stopActiveContext = true
// "true" = stop if any existing StreamingContext is running;
// "false" = dont stop, and let it run undisturbed, but your latest code may not be used
// === Configurations for Spark Streaming ===
val batchIntervalSeconds = 1
val eventsPerSecond = 1000 // For the dummy source
// Verify that the attached Spark cluster is 1.4.0+
require(sc.version.replace(".", "").toInt >= 140, "Spark 1.4.0+ is required to run this notebook. Please attach it to a Spark 1.4.0+ cluster.")
Imports
Import all the necessary libraries. If you see any error here, you have to make sure that you have attached the necessary libraries to the attached cluster.
import org.apache.spark._
import org.apache.spark.storage._
import org.apache.spark.streaming._
Discretized Streams (DStreams)
Discretized Stream or DStream is the basic abstraction provided by Spark Streaming. It represents a continuous stream of data, either the input data stream received from source, or the processed data stream generated by transforming the input stream. Internally, a DStream is represented by a continuous series of RDDs, which is Spark?s abstraction of an immutable, distributed dataset (see Spark Programming Guide for more details). Each RDD in a DStream contains data from a certain interval, as shown in the following figure.

Setup: Define the function that sets up the StreamingContext
In this we will do two things.
- Define a custom receiver as the dummy source (no need to understand this)
- this custom receiver will have lines that end with a random number between 0 and 9 and read:
I am a dummy source 2 I am a dummy source 8 ...
- this custom receiver will have lines that end with a random number between 0 and 9 and read:
This is the dummy source implemented as a custom receiver. No need to understand this now.
// This is the dummy source implemented as a custom receiver. No need to understand this.
import scala.util.Random
import org.apache.spark.streaming.receiver._
class DummySource(ratePerSec: Int) extends Receiver[String](StorageLevel.MEMORY_AND_DISK_2) {
def onStart() {
// Start the thread that receives data over a connection
new Thread("Dummy Source") {
override def run() { receive() }
}.start()
}
def onStop() {
// There is nothing much to do as the thread calling receive()
// is designed to stop by itself isStopped() returns false
}
/** Create a socket connection and receive data until receiver is stopped */
private def receive() {
while(!isStopped()) {
store("I am a dummy source " + Random.nextInt(10))
Thread.sleep((1000.toDouble / ratePerSec).toInt)
}
}
}
Let's try to understand the following creatingFunc to create a new StreamingContext and setting it up for word count and registering it as temp table for each batch of 1000 lines per second in the stream.
var newContextCreated = false // Flag to detect whether new context was created or not
// Function to create a new StreamingContext and set it up
def creatingFunc(): StreamingContext = {
// Create a StreamingContext
val ssc = new StreamingContext(sc, Seconds(batchIntervalSeconds))
// Create a stream that generates 1000 lines per second
val stream = ssc.receiverStream(new DummySource(eventsPerSecond))
// Split the lines into words, and then do word count
val wordStream = stream.flatMap { _.split(" ") }
val wordCountStream = wordStream.map(word => (word, 1)).reduceByKey(_ + _)
// Create temp table at every batch interval
wordCountStream.foreachRDD { rdd =>
rdd.toDF("word", "count").registerTempTable("batch_word_count")
}
stream.foreachRDD { rdd =>
System.out.println("# events = " + rdd.count())
System.out.println("\t " + rdd.take(10).mkString(", ") + ", ...")
}
ssc.remember(Minutes(1)) // To make sure data is not deleted by the time we query it interactively
println("Creating function called to create new StreamingContext")
newContextCreated = true
ssc
}
Transforming and Acting on the DStream of lines
Any operation applied on a DStream translates to operations on the
underlying RDDs. For converting
a stream of lines to words, the flatMap operation is applied on each
RDD in the lines DStream to generate the RDDs of the wordStream DStream.
This is shown in the following figure.

These underlying RDD transformations are computed by the Spark engine. The DStream operations hide most of these details and provide the developer with a higher-level API for convenience.
Next reduceByKey is used to get wordCountStream that counts the words in wordStream.
Finally, this is registered as a temporary table for each RDD in the DStream.
Start Streaming Job: Stop existing StreamingContext if any and start/restart the new one
Here we are going to use the configurations at the top of the notebook to decide whether to stop any existing StreamingContext, and start a new one, or recover one from existing checkpoints.
// Stop any existing StreamingContext
// The getActive function is proviced by Databricks to access active Streaming Contexts
if (stopActiveContext) {
StreamingContext.getActive.foreach { _.stop(stopSparkContext = false) }
}
// Get or create a streaming context
val ssc = StreamingContext.getActiveOrCreate(creatingFunc)
if (newContextCreated) {
println("New context created from currently defined creating function")
} else {
println("Existing context running or recovered from checkpoint, may not be running currently defined creating function")
}
// Start the streaming context in the background.
ssc.start()
// This is to ensure that we wait for some time before the background streaming job starts. This will put this cell on hold for 5 times the batchIntervalSeconds.
ssc.awaitTerminationOrTimeout(batchIntervalSeconds * 5 * 1000)
Interactive Querying
Now let's try querying the table. You can run this command again and again, you will find the numbers changing.
%sql select * from batch_word_count
Try again for current table.
%sql select * from batch_word_count
Finally, if you want stop the StreamingContext, you can uncomment and execute the following
StreamingContext.getActive.foreach { _.stop(stopSparkContext = false) }
StreamingContext.getActive.foreach { _.stop(stopSparkContext = false) }
Let's do two more example applications of streaming involving live tweets.
More Pointers to Spark Streaming
Spark Streaming Common Sinks
Writing to S3
We will be storing large amounts of data in s3, Amazon's simple storage service.
Spark Streaming Tutorials
- Window Aggregations in Streaming - Has examples for the different window aggregations available in spark streaming
- Global Aggregations using updateStateByKey - Provides an example of how to do global aggregations
- Global Aggregations using mapWithState - From Spark 1.6, you can use the
mapWithStateinterface to do global aggregations more efficiently. - Joining DStreams - Has an example for joining 2 dstreams
- Joining DStreams with static datasets - Builds on the previous example and shows how to join DStreams with static dataframes or RDDs efficiently
Example Streaming Producers
Spark Streaming Applications
Scalable Data Science
prepared by Raazesh Sainudiin and Sivanand Sivaram
supported by
and