SDS-2.2, Scalable Data Science
Archived YouTube video of this live unedited lab-lecture:
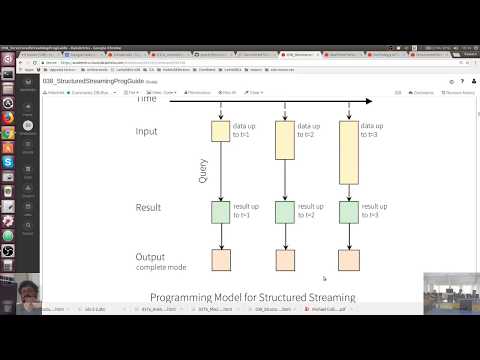
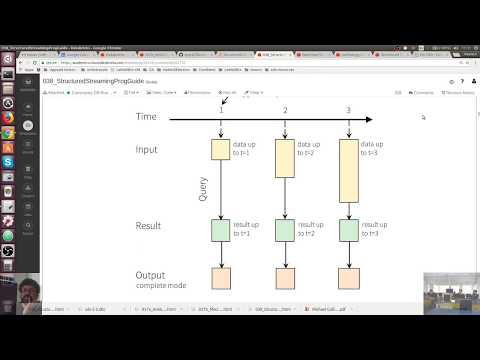
Task - do now
Write a mixture of two random graph models for file streaming later
We will use it as a basic simulator for timeseries of network data. This can be extended for specific domains like network security where extra fields can be added for protocols, ports, etc.
The raw ingredients are here... more or less.
Read the code from github
- https://github.com/apache/spark/blob/master/graphx/src/main/scala/org/apache/spark/graphx/util/GraphGenerators.scala
- Also check out: https://github.com/graphframes/graphframes/blob/master/src/main/scala/org/graphframes/examples/Graphs.scala
Let's focus on the two of the simplest (deterministic) graphs.
import scala.util.Random
import org.apache.spark.graphx.{Graph, VertexId}
import org.apache.spark.graphx.util.GraphGenerators
import org.apache.spark.sql.functions.lit // import the lit function in sql
import org.graphframes._
/*
// A graph with edge attributes containing distances
val graph: Graph[Long, Double] = GraphGenerators.logNormalGraph(sc, numVertices = 50, seed=12345L).mapEdges { e =>
// to make things nicer we assign 0 distance to itself
if (e.srcId == e.dstId) 0.0 else Random.nextDouble()
}
*/
val graph: Graph[(Int,Int), Double] = GraphGenerators.gridGraph(sc, 5,5)
import scala.util.Random import org.apache.spark.graphx.{Graph, VertexId} import org.apache.spark.graphx.util.GraphGenerators import org.apache.spark.sql.functions.lit import org.graphframes._ graph: org.apache.spark.graphx.Graph[(Int, Int),Double] = org.apache.spark.graphx.impl.GraphImpl@2afd1b5c
val g = GraphFrame.fromGraphX(graph)
val gE= g.edges.select($"src", $"dst".as("dest"), lit(1L).as("count")) // for us the column count is just an edge incidence
g: org.graphframes.GraphFrame = GraphFrame(v:[id: bigint, attr: struct<_1: int, _2: int>], e:[src: bigint, dst: bigint ... 1 more field]) gE: org.apache.spark.sql.DataFrame = [src: bigint, dest: bigint ... 1 more field] Warning: classes defined within packages cannot be redefined without a cluster restart. Compilation successful.
d3.graphs.force(
height = 500,
width = 500,
clicks = gE.as[d3.Edge])
val graphStar: Graph[Int, Int] = GraphGenerators.starGraph(sc, 10)
val gS = GraphFrame.fromGraphX(graphStar)
val gSE= gS.edges.select($"src", $"dst".as("dest"), lit(1L).as("count")) // for us the column count is just an edge incidence
d3.graphs.force(
height = 500,
width = 500,
clicks = gSE.as[d3.Edge])
Now, write code to simulate from a mixture of graphs models
- See
037a_...and037b_...notebooks for the file writing pattern. - First try, grid and star with 98%-2% mixture, respectively
- Second, try a truly random graph like lognormal degree distributed random graph and star
- Try to make a simulation of random networks that is closer to your domain of application (you can always drop in to python and R for this part - even using non-distributed algorithms for simulating large enough networks per burst).
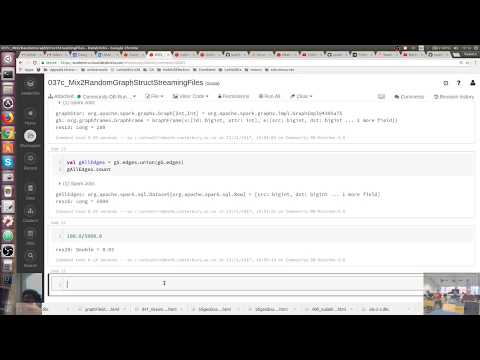
val graphGrid: Graph[(Int,Int), Double] = GraphGenerators.gridGraph(sc, 50,50)
val gG = GraphFrame.fromGraphX(graphGrid)
gG.edges.count
graphGrid: org.apache.spark.graphx.Graph[(Int, Int),Double] = org.apache.spark.graphx.impl.GraphImpl@160a43de gG: org.graphframes.GraphFrame = GraphFrame(v:[id: bigint, attr: struct<_1: int, _2: int>], e:[src: bigint, dst: bigint ... 1 more field]) res10: Long = 4900
val graphStar: Graph[Int, Int] = GraphGenerators.starGraph(sc, 101)
val gS = GraphFrame.fromGraphX(graphStar)
gS.edges.count
graphStar: org.apache.spark.graphx.Graph[Int,Int] = org.apache.spark.graphx.impl.GraphImpl@4395a75 gS: org.graphframes.GraphFrame = GraphFrame(v:[id: bigint, attr: int], e:[src: bigint, dst: bigint ... 1 more field]) res13: Long = 100
val gAllEdges = gS.edges.union(gG.edges)
gAllEdges.count
gAllEdges: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [src: bigint, dst: bigint ... 1 more field] res16: Long = 5000
100.0/5000.0
res20: Double = 0.02