SDS-2.2, Scalable Data Science
Archived YouTube video of this live unedited lab-lecture:
Power Forecasting
Student Project
by Gustav Björdal, Mahmoud Shepero and Dennis van der Meer
Loading data som JSON file
You should first import the cleaned data to dbfs:/FileStore/tables/forecasting/
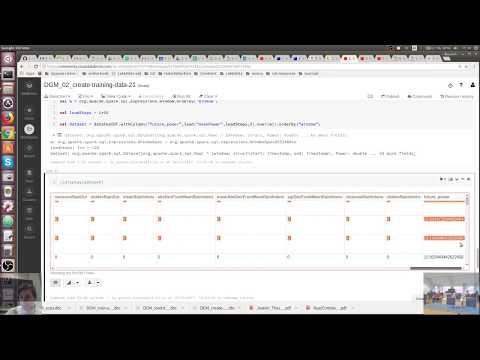
display(dbutils.fs.ls("dbfs:/FileStore/tables/forecasting"))
| path | name | size |
|---|---|---|
| dbfs:/FileStore/tables/forecasting/clean_data.json | clean_data.json | 7.1327975e7 |
// Note the schema to read our data
// Read the JSON files (stored as tables in inputPath) using the schema
val inputPath = "/FileStore/tables/forecasting/"
import org.apache.spark.sql.types._
val jsonSchema = new StructType()
.add("ID", StringType)
//.add("timeStamp", StringType)
.add("timeStamp", TimestampType)
.add("DataList",
new StructType()
.add("WXT530",
new StructType()
.add("DN", StringType) // Wind direction (degrees)
.add("SN", StringType) // Wind speed (m/s)
.add("GT3U", StringType) // Ambient temperature (Celsius)
.add("GM41", StringType) // Relative humidity (%)
.add("GP41", StringType) // Air pressure (mbar?)
.add("RC", StringType) // Cumulative rain over the last month (L?)
.add("RD", StringType) // Rain duration (s)
.add("RI", StringType) // Rain intensity (mm/h)
)
.add("MX41",
new StructType()
.add("P", StringType) // Power (kW)
)
)
inputPath: String = /FileStore/tables/forecasting/ import org.apache.spark.sql.types._ jsonSchema: org.apache.spark.sql.types.StructType = StructType(StructField(ID,StringType,true), StructField(timeStamp,TimestampType,true), StructField(DataList,StructType(StructField(WXT530,StructType(StructField(DN,StringType,true), StructField(SN,StringType,true), StructField(GT3U,StringType,true), StructField(GM41,StringType,true), StructField(GP41,StringType,true), StructField(RC,StringType,true), StructField(RD,StringType,true), StructField(RI,StringType,true)),true), StructField(MX41,StructType(StructField(P,StringType,true)),true)),true))
// Read a certain JSON file and turn it into a dataframe
val DF = spark.read
.format("json")
.schema(jsonSchema)
.option("header", "true")
.load(inputPath) // This immediately loads all files in inputPath
//DF.printSchema
DF.count
DF: org.apache.spark.sql.DataFrame = [ID: string, timeStamp: timestamp ... 1 more field] res2: Long = 367965
// Extract the columns that I want and rename them (timeStamp is now included, which saves some steps)
// In addition, cast them to double
val FinalDF = DF.select($"DataList.MX41".getItem("P").alias("Power").cast(DoubleType),
$"DataList.WXT530".getItem("DN").alias("WindDirection").cast(DoubleType),
$"DataList.WXT530".getItem("SN").alias("WindSpeed").cast(DoubleType),
$"DataList.WXT530".getItem("GT3U").alias("Temperature").cast(DoubleType),
$"DataList.WXT530".getItem("GM41").alias("RH").cast(DoubleType),
$"DataList.WXT530".getItem("GP41").alias("AP").cast(DoubleType),
$"DataList.WXT530".getItem("RC").alias("RainCumulative").cast(DoubleType),
$"DataList.WXT530".getItem("RD").alias("RainDur").cast(DoubleType),
$"DataList.WXT530".getItem("RI").alias("RainIntens").cast(DoubleType),
$"timeStamp")
FinalDF: org.apache.spark.sql.DataFrame = [Power: double, WindDirection: double ... 8 more fields]
//display(FinalDF.select($"Power",$"WindSpeed"))
//FinalDF.orderBy("timeStamp").show()
Exports:
FinalDF- DatasetleadDF- Dataset with a one-step lag